Обучение
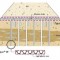
Обучение состоит из последовательности коррекций векторов, представляющих собой нейроны. На каждом шаге обучения из исходного набора данным случайно выбирается один из векторов, а затем производится поиск наиболее похожего на него вектора коэффициентов нейронов. При этом выбирается нейрон-победитель, который наиболее похож на вектор входов. Под похожестью в данной задаче понимается расстояние между векторами, обычно вычисляемое в евклидовом пространстве. Таким образом, если обозначит нейрон-победитель как c, то получим $\mid\mid\mathbf {x}- \mathbf {w_c}\mid \mid = \min_i $ $\{ \mid \mid \mathbf {x}- \mathbf {w_i}\mid \mid \}$.
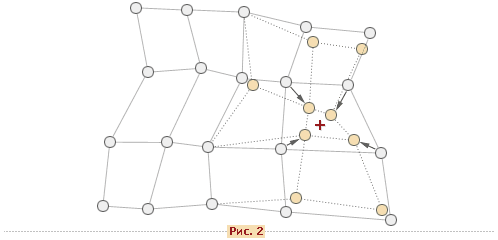
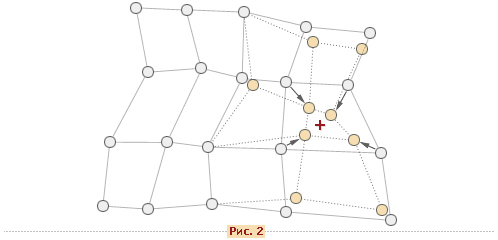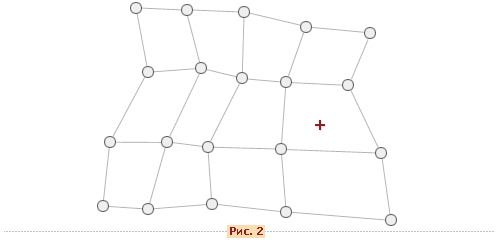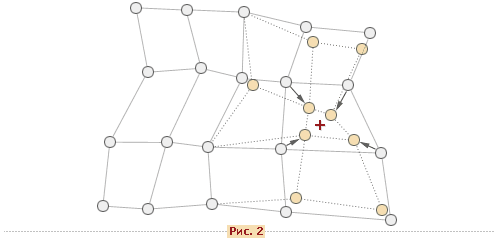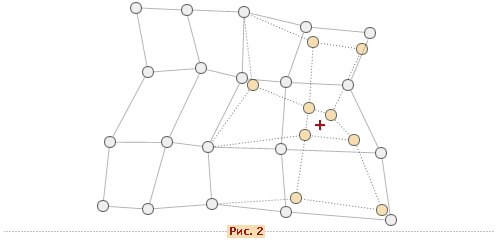
После того, как найден нейрон-победитель производится корректировка весов нейросети. При этом вектор, описывающий нейрон-победитель и вектора, описывающие его соседей в сетке перемещаются в направлении входного вектора. Это проиллюстрировано на рисунке 2 для двумерного вектора.
При этом для модификации весовых коэффициентов используется формула:
$w_i (t+1)= \mathbf w_i(t) + h_{ci}(t) * $ ,
где t обозначает номер эпохи (дискретное время). При этом вектор x(t) выбирается случайно из обучающей выборки на итерации t. Функция h(t) называется функцией соседства нейронов. Эта функция представляет собой невозрастающую функцию от времени и расстояния между нейроном-победителем и соседними нейронами в сетке. Эта функция разбивается на две части: собственно функцию расстояния и функции скорости обучения от времени. где r определяет положение нейрона в сетке.
Обычно применяется одни из двух функций от расстояния: простая константа
$h(d,t) =
\begin{cases}
const, d \leq\sigma (t)\\
0, d >\sigma (t)
\end{cases}$. При этом лучший результат получается при использовании Гауссовой функции расстояния. При этом является убывающей функцией от времени. Часто эту величину называют радиусом обучения, который выбирается достаточно большим на начальном этапе обучения и постепенно уменьшается так, что в конечном итоге обучается один нейрон-победитель. Наиболее часто используется функция, линейно убывающая от времени.
Рассмотрим теперь функцию скорости обучения $a(t)$. Эта функция также представляет собой функцию, убывающую от времени. Наиболее часто используются два варианта этой функции: линейная и обратно пропорциональная времени вида ${a(t)} =\frac {\mbox A}{\mbox{t + B}}$, где A и B это константы. Применение этой функции приводит к тому, что все вектора из обучающей выборки вносят примерно равный вклад в результат обучения.
Обучение состоит из двух основных фаз: на первоначальном этапе выбирается достаточно большое значение скорости обучения и радиуса обучение, что позволяет расположить вектора нейронов в соответствии с распределением примеров в выборке, а затем производится точная подстройка весов, когда значения параметров скорости обучения много меньше начальных. В случае использования линейной инициализации первоначальный этап грубой подстройки может быть пропущен.
Производительность
Программы, использующие MapReduce, не всегда будут работать быстро. Главным преимуществом этой модели программирования является оптимизированное распределение данных между узлами и небольшое количество кода, которое требуется написать программисту
Однако на практике пользователь программы должен принять во внимание этап распределения данных, в частности, функция разделения данных и количество данных на выходе функции Map могут очень сильно влиять на производительность. Дополнительные модули, такие как функция Combiner, могут помочь уменьшить количество данных, записываемых на диск и передаваемых через сеть.
При написании программы пользователь должен найти и выбрать хороший компромисс между вычислительной и коммуникационной сложностью. Коммуникационная сложность превосходит над вычислительной сложностью, и многие реализации MapReduce были разработаны, чтобы записывать сведения обо всех коммуникациях в распределённое хранение для аварийного восстановления.
Для задач, которые решаются быстро на нераспределённых системах, а входные данные помещаются в оперативную память одного компьютера или небольшого кластера, использование фреймворка MapReduce неэффективно. Так как эти фреймворки разработаны, чтобы иметь возможность восстановления целых узлов кластера во время вычислений, они записывают в распределённое хранилище промежуточные результаты работы. Такая защита от сбоев – очень дорогая процедура и окупается, только когда в вычислениях участвует множество компьютеров, а при выходе одного из них из строя проще всего перезапустить присвоенную ему задачу на другом узле.
Тематическая карта
Позволяет создать цветовую дифференциацию объектов слоя по любой колонке, содержащей цифровые значения.
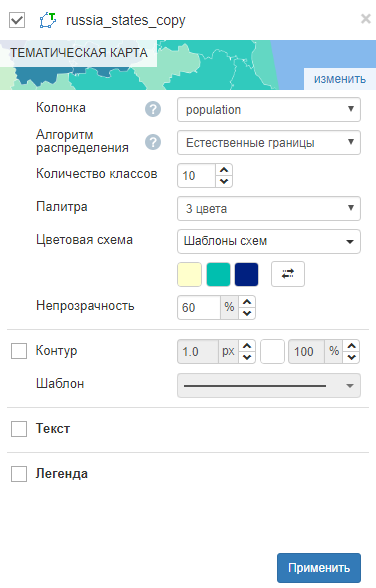
Настройки данного типа визуализации позволяют:
- выбрать колонку, по которой будет производится цветовая дифференциация;
- выбрать параметры группировки объектов (алгоритм распределения):
- Равные интервалы – алгоритм разбивает диапазон значений атрибута на поддиапазоны равного размера;
- Квантили – каждый класс содержит одинаковое число объектов (такая классификация хорошо подходит для линейно распределенных данных);
- Естественные границы (Jenks’ Natural Breaks algorithm) – границы классов определяются таким образом, чтобы сгруппировать схожие значения и максимально увеличить различия между классами.
- установить количество классов (интервалов), по которым проводится группировка объектов для цветовой дифференциации. От количества классов зависит количество оттенков одного цвета в пределах выбранной палитры;
- выбрать палитру (количество цветов) для цветовой дифференциации. Выбрать можно палитру, состоящую из 2-х или 3-х цветов;
- выбрать из нескольких шаблонов сочетания цветов (цветовая схема) для цветовой дифференциации, а также изменить цветовую гамму по собственному усмотрению при помощи встроенного инструмента выбора цвета из цветового пространства RGB (color picker);
- установить степень прозрачности виртуального слоя над нижестоящими слоями или подложкой карты;
- настроить внешний вид контура (границы) между объектами тематической карты. Настройка позволяет выбрать тип линии, её толщину в пикселях, а также её цвет и степень прозрачности;
- настроить подписи к объектам на тематической карте (текст). Настройка позволяет выбрать колонку, значения которой будут отображаться в подписи к объекту, а также стиль этой подписи (шрифт, размер, контур);
- настроить отображение легенды на публичной карте. Настройка позволяет включить отображение легенды на публичной карте, а также дать легенде название и настроить вывод отображения значений (условные знаки) визуализации.
Примечание: Если не указано иного, то значения всех настроек, касающихся размеров, длины, ширины, положения элементов указываются в пикселях (px)
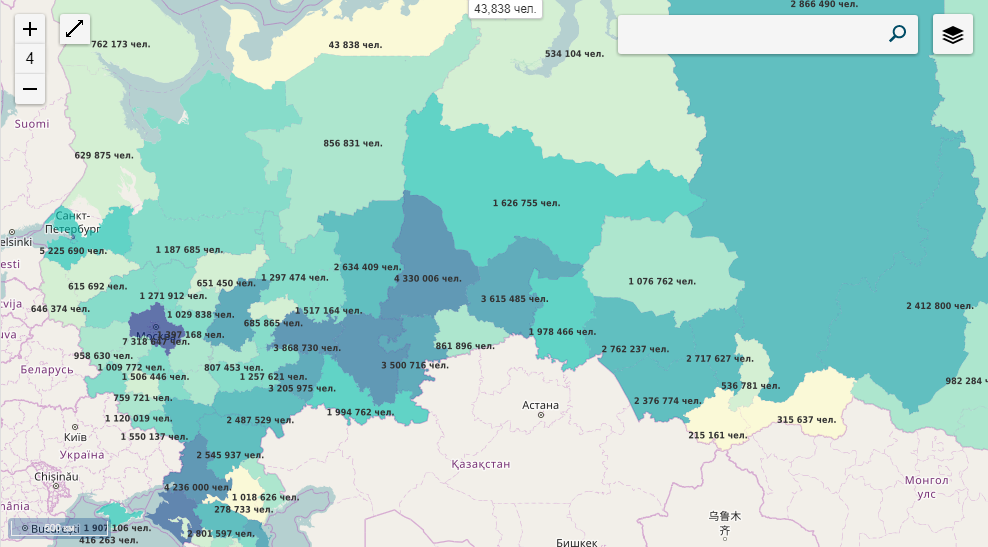
Результат применения визуализации типа Тематическая карта,:
Назначение и области применения
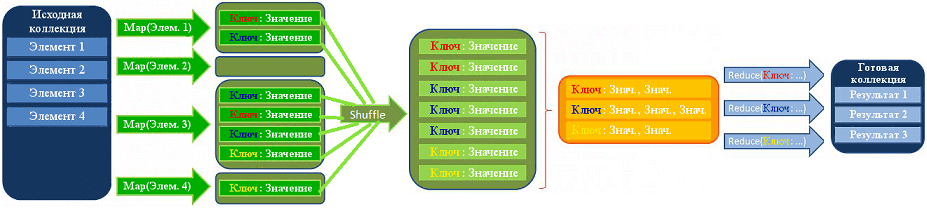
MapReduce можно по праву назвать главной технологией Big Data, т.к. она изначально ориентирована на параллельные вычисления в распределенных кластерах. Суть MapReduce состоит в разделении информационного массива на части, параллельной обработки каждой части на отдельном узле и финального объединения всех результатов.
Программы, использующие MapReduce, автоматически распараллеливаются и исполняются на распределенных узлах кластера, при этом исполнительная система сама заботится о деталях реализации (разбиение входных данных на части, разделение задач по узлам кластера, обработка сбоев и сообщение между распределенными компьютерами). Благодаря этому программисты могут легко и эффективно использовать ресурсы распределённых Big Data систем.
Технология практически универсальна: она может использоваться для индексации веб-контента, подсчета слов в большом файле, счётчиков частоты обращений к заданному адресу, вычисления объём всех веб-страниц с каждого URL-адреса конкретного хост-узла, создания списка всех адресов с необходимыми данными и прочих задач обработки огромных массивов распределенной информации. Также к областям применения MapReduce относится распределённый поиск и сортировка данных, обращение графа веб-ссылок, обработка статистики логов сети, построение инвертированных индексов, кластеризация документов, машинное обучение и статистический машинный перевод. Также MapReduce адаптирована под многопроцессорные системы, добровольные вычислительные, динамические облачные и мобильные среды .
Преимущества
Преимущество MapReduce заключается в том, что он позволяет распределенно производить операции предварительной обработки и свертки. Операции предварительной обработки работают независимо друг от друга и могут производиться параллельно. Аналогично множество рабочих узлов могут осуществлять свертку: для этого необходимо только чтобы все результаты предварительной обработки с одним значением ключа обрабатывались одним рабочим узлом в один момент времени. Хотя этот процесс может быть менее эффективным по сравнению с более последовательными алгоритмами, MapReduce может быть применен к большим объёмам данных, которые невозможно обработать последовательно в разумное время из-за недостатка памяти. Так, MapReduce может быть использован для сортировки петабайта данных, и это займет всего несколько часов. Параллелизм также дает некоторые возможности восстановления после частичных сбоев серверов: если в рабочем узле возникает сбой, то его работа может быть передана другому рабочему узлу (при условии, что входные данные для проводимой операции доступны).
Критика
Отсутствие новых идей
Дэвид ДеВитт и Майкл Стоунбрейкер, компьютерные специалисты, специализирующиеся на параллельных базах данных и распределённых архитектурах, критиковали ширину области задач, для которых может применяться MapReduce. Они назвали интерфейс реализации слишком низкоуровневым и поставили под сомнение заявление разработчиков о том, что он представляет новый этап развития технологий. Одним из аргументов стало сравнение MapReduce с Teradata, системой массовой параллельной обработки, существующей уже больше двух десятилетий, а также с языком CODASYL («программирование на низкоуровневом языке, производящее низкоуровневые манипуляции»). Также отсутствие поддержки схем не позволяет улучшать производительность с помощью присущих обыкновенным базам данных B-деревьев и хэш-разбиения, однако некоторые проблемы позволяют решить такие проекты как Pig, Sawzall, Apache Hive, YSmart, HBase и BigTable.
Грег Йоргенсен опубликовал статью, опровергающую эти взгляды. Йоргенсен полагает, что анализ ДеВитта и Стоунбрейкера полностью безоснователен, так как MapReduce никогда не разрабатывался и не позиционировался как база данных.
Сначала ДеВитт, а затем и Стоунбрейкер опубликовали в 2009 году детальное исследование производительности реализации MapReduce в Hadoop и подходов СУБД в некоторых аспектах. Они сделали заключение, что реляционные базы данных предлагают настоящие преимущества для многих способов использования данных, особенно для их сложной обработки, или когда данные располагаются в хранилище крупного предприятия, однако использование MapReduce может оказаться проще для начинающих пользователей или несложных задач.
Патент на MapReduce побудил множество споров, так как реализация MapReduce очень похожа на существующие продукты. Например, операции map и reduce могут быть легко реализованы на языке базы данных Oracle PL/SQL, а также неявно предоставляются в таких распределённых базах данных как Clusterpoint XML или MongoDB NoSQL.
Ограниченные возможности фреймворка
Программы MapReduce должны описывать ациклический поток данных: этапы Map и Reduce, управляемые пакетным планировщиком задач, строго следуют один за другим. Эта парадигма делает сложными повторяющиеся запросы данных и налагает ограничения, которые ощутимы в таких областях, как машинное обучение, которое состоит их итеративных алгоритмов, обращающихся к одному и тому же набору данных много раз.
Инструкция как войти в настройки роутера через http://192.168.0.1
После того как Вы ввели в адресную строку браузера 192.168.0.1 Вы оказываетесь в так называемом Личном Кабинете роутера, в котором и будут происходить все настройки. Авторизация, первое что попадается на глаза это запрос логина и пароля для входа. Это, как правило:
- Пароль: admin;
- Логин: admin
Эту информацию можно найти либо на упаковке, либо на самом маршрутизаторе, на котором есть наклейка с технической информацией, снизу. Стандартные логин и пароль могли быть изменены. Поэтому, если в вас не получается зайти в роутер 192.168.0.1, сбросьте все настройки через фукцию и одноименную кнопку Reset на тыльной стороне устройства, куда подсоединяются LAN кабели и шнур питания.
После того как будут введены эти данные откроется окно с основными настройками. Все настройки интуитивно понятны и каждый сможет их установить самостоятельно. Они однотипны. То есть имеют общие схожие параметры. Чтобы узнать о них подробнее, смотрите видео.
Давайте рассмотрим в качестве примера подключение маршрутизатора TP-link. Действия будут следующими:
- Выбираете быструю настройку;
- Выбор страны, города или региона в котором будет использоваться маршрутизатор;
- Выбор провайдера, который Вам предоставляет услуги доступа в интернет;
- Следует выбрать тип подключения, если интернет скоростной, то нужно выбирать PPPoE;
- Далее устанавливаются имя пользователя и пароль – их Вам предоставит провайдер;
- Потом проверьте, чтобы беспроводной режим на устройстве был включен;
- И в заключении следует придумать пароль, который будет использоваться для подключения по WI-FI. Эта функция находится в графе (защита беспроводного режима или Wireless Settings).
После выполнения этих не сложных действий необходимо нажать кнопку — перегрузить, для того чтобы внесtнные Вами изменения в настройки маршрутизатора вступили в силу.
Выполнив перезагрузку и дождавшись, когда индикаторы на устройстве загорятся, а некоторые замигают, можно пытаться входить в интернет. Если он работает, значит вы все сделали правильно. Вот и все хитрости настроек. Теперь можете пользоваться интернетом со всех имеющихся гаджетов.
Цель модели
Входные данные обычно имеют большой объём, и вычисления приходится распределять по сотням или даже тысячам машин, чтобы иметь возможность решить задачу в разумный промежуток времени. Проблемы распараллеливания вычислений, распределения данных и обработки сбоев заставляют отказаться от простой модели вычислений с большим объёмом сложного кода. В Google отреагировали на эту сложность и разработали новую абстракцию, которая позволяет легко производить необходимые вычисления, но скрывает все детали распараллеливания, отказоустойчивости, распределения данных и балансировки нагрузки в своих библиотеках.
Вдохновением для этой абстракции были функции map и reduce, представленные во многих функциональных языках программирования. В Google осознали, что две эти операции применяются в большинстве задач обработки больших данных.
Применение алгоритма
Так как алгоритм SOM сочетает в себе два основных направления – векторное квантование и проецирование, то можно найти и основные применения этого алгоритма. Данную методику можно использовать для поиска и анализа закономерностей в исходных данных. При этом, после того, как нейроны размещены на карте, полученная карта может быть отображена. Рассмотрим различные способы отображения полученной карты.
Раскраска, порожденная отдельными компонентами
При данном методе отрисовки полученную карту можно представить в виде слоеного пирога. Каждый слой которого представляет собой раскраску, порожденную одной из компонент исходных данных. Полученный набор раскрасок может использоваться для анализа закономерностей, имеющихся между компонентами набора данных. После формирования карты мы получаем набор узлов, который можно отобразить в виде двумерной картинки. При этом каждому узлу карты можно поставить в соответствие участок на рисунке, четырех или шестиугольный, координаты которого определяются координатами соответствующего узла в решетке. Теперь для визуализации осталось только определить цвет ячеек этой картинки. Для этого и используются значения компонент. Самый простой вариант – использование градаций серого. В этом случае ячейки, соответствующие узлам карты, в которые попали элементы с минимальными значениями компонента или не попало вообще ни одной записи, будут изображены черным цветом, а ячейки, в которые попали записи с максимальными значениями такого компонента, будут соответствовать ячейки белого цвета. В принципе можно использовать любую градиентную палитру для раскраски.
Полученные раскраски в совокупности образуют атлас, отображающий расположение компонент, связи между ними, а также относительное расположение различных значений компонент.
Отображение кластеров
Кластером будет являться группа векторов, расстояние между которыми внутри этой группы меньше, чем расстояние до соседних групп. Структура кластеров при использовании алгоритма SOM может быть отображена путем визуализации расстояния между опорными векторами (весовыми коэффициентами нейронов). При использовании этого метода чаще всего используется унифицированная матрица расстояний (u-matrix). При использовании этого метода вычисляется расстояние между вектором весов нейрона в сетке и его ближайшими соседями. Затем эти значения используются для определения цвета, которым этот узел будет отрисован. Обычно используют градации серого, причем чем больше расстояние, тем темнее отрисовывается узел. При таком использовании узлам с наибольшим расстоянием между ними и соседями соответствует черный цвет, а близлежащим узлам – белый.
Надёжность
Надёжность MapReduce достигается за счёт распределения операции обработки данных по всем узлам сети. Мастер периодически опрашивает каждый рабочий узел для получения статуса или результата работы. Если узел не отвечает в течение установленного времени, мастер начинает считать его аварийным и назначает его работу другому узлу.
В узлах применяются атомарные операции именования выходных файлов для проверки, что в каждый момент не запущены конфликтующие параллельные потоки.
Так как операция свёртки плохо распараллеливается, и именно в узле хранится обрабатываемая часть данных, мастер предпринимает попытки запуска свёртки на том же самом или на близлежащих узлах.
Не все реализации MapReduce обязательно обладают высокой надёжностью. Например, в ранних версиях Hadoop примитив мастер-узла NameNode был единой точкой отказа распределённой файловой системы. Более поздние версии Hadoop стали обладать большей активной и пассивной отказоустойчивостью.
История развития главной технологии Big Data
Авторами этой вычислительной модели считаются сотрудники Google Джеффри Дин (Jeffrey Dean) и Санджай Гемават (Sanjay Ghemawat), взявшие за основу две процедуры функционального программирования: map, применяющая нужную функцию к каждому элементу списка, и reduce, объединяющая результаты работы map . В процессе вычисления множество входных пар ключ/значение преобразуется в множество выходных пар ключ/значение .
Изначально название MapReduce было запатентовано корпорацией Google, но по мере развития технологий Big Data стало общим понятием мира больших данных. Сегодня множество различных коммерческих, так и свободных продуктов, использующих эту модель распределенных вычислений: Apache Hadoop, Apache CouchDB, MongoDB, MySpace Qizmt и прочие Big Data фреймворки и библиотеки, написанные на разных языках программирования . Среди других наиболее известных реализаций MapReduce стоит отметить следующие 5]:
- Greenplum — коммерческая реализация с поддержкой языков Python, Perl, SQL и пр.;
- GridGain — бесплатная реализация с открытым исходным кодом на языке Java;
- Phoenix — реализация на языке С с использованием разделяемой памяти;
- MapReduce реализована в графических процессорах NVIDIA с использованием CUDA;
- Qt Concurrent — упрощённая версия фреймворка, реализованная на C++, для распределения задачи между несколькими ядрами одного компьютера;
- CouchDB использует MapReduce для определения представлений поверх распределённых документов;
- Skynet — реализация с открытым исходным кодом на языке Ruby;
- Disco — реализация от компании Nokia, ядро которой написано на языке Erlang, а приложения можно разрабатывать на Python;
- Hive framework — надстройка с открытым исходным кодом от Facebook, позволяющая комбинировать подход MapReduce и доступ к данным на SQL-подобном языке;
- Qizmt — реализация с открытым исходным кодом от MySpace, написанная на C#;
- DryadLINQ — реализация от Microsoft Research на основе PLINQ и Dryad.
 MapReduce — это разделение, параллельная обработка и свертка распределенных результатов
MapReduce — это разделение, параллельная обработка и свертка распределенных результатов
Основы
Алгоритм функционирования самообучающихся карт (Self Organizing Maps – SOM) представляет собой один из вариантов кластеризации многомерных векторов. Примером таких алгоритмов может служить алгоритм k-ближайших средних (k-means). Важным отличием алгоритма SOM является то, что в нем все нейроны (узлы, центры классов…) упорядочены в некоторую структуру (обычно двумерную сетку). При этом в ходе обучения модифицируется не только нейрон-победитель, но и его соседи, но в меньшей степени. За счет этого SOM можно считать одним из методов проецирования многомерного пространства в пространство с более низкой размерностью. При использовании этого алгоритма вектора, схожие в исходном пространстве, оказываются рядом и на полученной карте.
Программное обеспечение
При работе с инклинометром используется встроенное и автономное программное обеспечение (далее – ПО).
Встроенное ПО FLN204 реализует функциональность инклинометра и выполняет следующие функции:
– производит измерение углов;
– поддерживает обмен данными по физическому интерфейсу RS485 по протоколу Modbus RTU с внешними устройствами;
– производит тестирование чувствительных элементов инклинометра.
Автономное ПО «FLNTools» функционирует под управлением операционной системы Windows и состоит из двух программ «FLNView» и «FLNDrive».
ПО «FLNView» предназначено для сбора и отображения результатов измерения.
ПО «FLNDrive» предназначено для начальной конфигурации инклинометра.
Уровень защиты ПО «Средний», в соответствии с Р 50.2.077- 2014.
Влияние ПО на метрологические характеристики учтено при нормировании метрологических характеристик.
Таблица 2 – Идентификационные данные программного обеспечения
|
Идентиф икационные признаки |
Значение |
||
|
Встроенное ПО |
Автономное ПО |
||
|
Идентиф икационное наименование ПО |
FLN204 |
FLNView |
FLNDrive |
|
Номер версии (идентификационный номер) ПО |
Не ниже 1.0.0 |
Не ниже 1.0.0 |
Не ниже 1.0.0 |
|
Идентиф икационные признаки |
Значение |
||
|
Встроенное ПО |
Автономное ПО |
||
|
Цифровой идентификатор ПО |
88ec341fcb5d4fe707b21 9d652f324dab7146107 |
7b512a4e2e3f0138cfe1 e0b2f3bc127db33ea2aa |
3c27255f8f6840e4febab 36d84bb7873331504fc |
|
Алгоритм вычисления идентификатора ПО |
SHA1 |
SHA1 |
SHA1 |
Пример алгоритма
Канонический пример приложения, написанного с помощью MapReduce – это программа на псевдокоде, подсчитывающая количество различных слов в наборе документов:
// Функция, используемая рабочими узлами на Map-шаге для обработки пар ключ-значение из входного потока
void map(String name, String document)
// Входные данные:
// name – название документа
// document – содержимое документа
for each word w in document
EmitIntermediate(w, "1");
// Функция, используемая рабочими узлами на Reduce-шаге для обработки пар ключ-значение, полученных на Map-шаге
void reduce(String word, Iterator partialCounts)
// Входные данные:
// word – слово
// partialCounts – список группированных промежуточных результатов. Количество записей в partialCounts и есть требуемое значение
int result = ;
for each v in partialCounts
result += parseInt(v);
Emit(AsString(result));
Описание
Инклинометр имеет моноблочное исполнение и состоит из чувствительного элемента с аналоговым выходом, предусилителя, аналого-цифрового преобразователя, микроконтроллера и приемо-передатчиков интерфейса RS-485, установленных в металлический корпус.
В качестве чувствительного элемента используется микромеханический двухосевой акселерометр. Аналоговый выходной сигнал акселерометра, пропорциональный проекции ускорения свободного падения на ось чувствительности, преобразуется 24 битным аналогоцифровым преобразователем в цифровую форму и передается в микроконтроллер, который пересчитывает его в значения углов наклона. Одновременно с информацией об углах наклона передаются данные о температуре чувствительного элемента. Микроконтроллер обеспечивает привязку измерений инклинометра к базовой поверхности корпуса и их температурную компенсацию.
На корпусе инклинометра установлены разъёмы для подключения кабелей линии связи и передачи результатов измерений на ПК.
Инклинометры позволяют производить измерения углов в двух режимах:
– однократные или непрерывные абсолютные измерения углов наклона конструкций;
– непрерывные относительные измерения изменений углов наклона конструкций. Инклинометры имеют несколько исполнений, которые отличаются ориентацией
измерительных осей, условиями эксплуатации и массогабаритными параметрами. Исполнения инклинометров представлены в таблице 1.
Условное обозначение инклинометра:
* * *
Инклинометр ФЛН-20х-хх х х
|
Номер версии: 3**, 4 | |
||
|
Тип исполнения: |
||
|
01, 02, 03, 04, 05. (См. Таблицу 1) |
||
|
Способ установки1: В, А |
||
|
Наличие терминатора линии RS-485*: |
||
|
Т |
|
Исполнение |
Условия применения |
Способ установки инклинометра |
Наличие терминатора линии RS-485 |
Обозначение основного конструкторского документа |
|
ФЛН-204-01 |
Для применения в стандартных условиях |
На горизонтальную площадку |
нет |
ФАМС.401267.005 |
|
ФЛН-204-01Т |
есть |
ФАМС.401267.005-03 |
||
|
ФЛН-204-01В |
На вертикальную площадку в основной ориентации |
нет |
ФАМС.401267.005-01 |
|
|
ФЛН-204-01ВТ |
есть |
ФАМС.401267.005-04 |
||
|
ФЛН-204-01 А |
На вертикальную площадку в альтернативной ориентации |
нет |
ФАМС.401267.005-02 |
|
|
ФЛН-204-01АТ |
есть |
ФАМС.401267.005-05 |
||
|
ФЛН-204-02 |
Для специальных применений |
В оболочку в горизонтальной ориентации |
нет |
ФАМС.401267.006 |
|
ФЛН-204-02Т |
есть |
ФАМС.401267.006-03 |
||
|
ФЛН-204-02В |
В оболочку в вертикальной ориентации |
нет |
ФАМС.401267.006-01 |
|
|
ФЛН-204-02ВТ |
есть |
ФАМС.401267.006-04 |
||
|
ФЛН-204-02А |
В оболочку в вертикальной альтернативной ориентации |
нет |
ФАМС.401267.006-02 |
|
|
ФЛН-204-02АТ |
есть |
ФАМС.401267.006-05 |
||
|
ФЛН-204-03 |
Для применения внутри бетонного массива |
Внутри бетонного массива в горизонтальной ориентации |
нет |
ФАМС.401267.007 |
|
ФЛН-204-03Т |
есть |
ФАМС.401267.007-03 |
||
|
ФЛН-204-03В |
Внутри бетонного массива в вертикальной ориентации |
нет |
ФАМС.401267.007-01 |
|
|
ФЛН-204-03ВТ |
есть |
ФАМС.401267.007-04 |
||
|
ФЛН-204-03А |
Внутри бетонного массива в вертикальной альтернативной ориентации |
нет |
ФАМС.401267.007-02 |
|
|
ФЛН-204-03АТ |
есть |
ФАМС.401267.007-05 |
||
|
ФЛН-204-04 |
Для применения в условиях повышенной влажности |
На горизонтальную площадку |
нет |
ФАМС.401267.008 |
|
ФЛН-204-04Т |
есть |
ФАМС.401267.008-03 |
||
|
ФЛН-204-04В |
На вертикальную площадку в основной ориентации |
нет |
ФАМС.401267.008-01 |
|
|
ФЛН-204-04ВТ |
есть |
ФАМС.401267.008-04 |
||
|
ФЛН-204-04А |
На вертикальную площадку в альтернативной ориентации |
нет |
ФАМС.401267.008-02 |
|
|
ФЛН-204-04АТ |
есть |
ФАМС.401267.008-05 |
|
Исполнение |
Условия применения |
Способ установки инклинометра |
Наличие терминатора линии RS-485 |
Обозначение Основного конструкторского документа |
|
ФЛН-204-05 |
Для применения в условиях Крайнего Севера |
На горизонтальную площадку |
нет |
ФАМС.401267.009 |
|
ФЛН-204-05Т |
есть |
ФАМС.401267.009-03 |
||
|
ФЛН-204-05В |
На вертикальную площадку в основной ориентации |
нет |
ФАМС.401267.009-01 |
|
|
ФЛН-204-05ВТ |
есть |
ФАМС.401267.009-04 |
||
|
ФЛН-204-05А |
На вертикальную площадку в альтернативной ориентации |
нет |
ФАМС.401267.009-02 |
|
|
ФЛН-204-05АТ |
есть |
ФАМС.401267.009-05 |
||
|
ФЛН-203-В |
Для специальных применений |
В оболочку в вертикальной альтернативной ориентации |
нет |
ФАМС.401267.004 |
Общий вид инклинометра представлен на рисунке 1.
Для защиты от несанкционированного доступа выполнено опломбирование головки одного из винтов крепления крышки инклинометра.
Схема пломбировки от несанкционированного доступа и обозначение места нанесения знака утверждения типа СИ представлены на рисунке 2.
Рисунок 2 – Схема пломбировки от несанкционированного доступа и обозначение места нанесения знака утверждения типа СИ
Технические характеристики (см. колонку товара МВ210-204)
|
Модификация |
МВ210-202 |
МВ210-204 |
МВ210-221 |
|
Входы |
|||
|
Количество входов |
20 DI |
9 + 6 DI | |
|
Тип входов |
|
|
|
|
Характеристики дискретных входов (DI) |
|||
|
Гальваническая развязка входов |
– |
||
|
Режимы работы |
|
|
Для сигналов ~230 В:
Для сигналов =24 В:
|
|
Макс. частота входного сигнала |
определение логического уровня |
400 Гц |
|
|
подсчет числа импульсов |
100 кГц (только 1 – 8 DI) |
400 Гц |
|
|
измерение частоты |
100 кГц (только 1 – 8 DI) |
– |
|
|
обработка сигналов энкодера |
100 кГц |
– |
|
|
Мин. длительность импульса |
5 мкс (1 – 8 DI) |
1 мс |
|
|
1 мс (9 – 20 DI) |
|||
|
Напряжение питания входов |
24±3 В |
24±3 В для транзисторных ключей Для «сухих контактов» питание не требуется! |
|
|
Сопротивление контактов (ключа) и соединительных проводов, подключаемых к дискретному входу |
– |
не более 100 Ом |
|
|
Ток «логической единицы» |
не менее 5,5 мА |
– |
|
|
Ток «логического нуля» |
не более 1,2 мА |
– |
|
|
Напряжение «логической единицы» |
8,8…30 В |
– |
|
|
Напряжение «логического нуля» |
0…6,1 В |
– |
|
|
Питание |
|||
|
Напряжение питания |
=10…48 (номинальное =24)В |
||
|
Потребляемая мощность |
не более 4 Вт при питании =24 В |
не более 5 Вт при питании =24 В | |
|
Защита от переполюсовки |
есть |
||
|
Тип питания часов реального времени |
батарея CR2032 |
||
|
Конструктивное исполнение |
|||
|
Габаритные размеры |
(123×83×42)±1мм |
||
|
Степень защиты |
IP20 |
||
|
Монтаж |
на DIN-рейку / на стену |
||
|
Средний срок службы |
10 лет |
||
|
Масса |
не более 0,4 кг |
||
|
Условия эксплуатации |
|||
|
Температура окружающего воздуха |
-40…+55 °С |
||
|
Относительная влажность воздуха (при +25 °С и ниже без конденсации влаги) |
не более 80 % |
||
|
Комплектность |
|||
|
Модуль |
1 шт. |
||
|
Паспорт и гарантийный талон |
1 экз. |
||
|
Краткое руководство по эксплуатации |
1 экз. |
||
|
Диск с ПО |
1 шт. |
||
|
Кабель патч-корд UTP 5e 150 мм |
1 шт. |
||
|
Клемма питания 2EGTK-5-02P-14 |
1 шт. |
||
|
Заглушка Ethernet |
1 шт. |
| Технические характеристики | |
|---|---|
| Протокол передачи данных |
|
| DI (дискретный ввод) | 20 |
Список источников
- http-192-168-0-1.ru
- www.bigdataschool.ru
- ru.bmstu.wiki
- insat.ru
- all-pribors.ru
- docs.orbismap.ru
- basegroup.ru