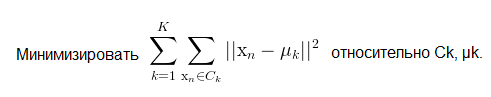
Математическая база
Алгоритм k-средних принимает в качестве входных данных набор данных X, содержащий N точек, а также параметр K, задающий требуемое количество кластеров. На выходе получаем набор из K центроидов кластеров, кроме того, всем точкам множества X присваиваются метки, относящие их к определенному кластеру. Все точки в пределах данного кластера расположены ближе к своему центроиду, чем к любому другому центроиду.
Математическое выражение для K кластеров Ck и K центроидов μk имеет вид:
Алгоритм Ллойда
К сожалению, задача является NP-сложной. Тем не менее, существует итерационный метод, известный как алгоритм Ллойда, который сходится (хотя и к локальному минимуму) в пределах небольшого количества итераций. В рамках данного алгоритма поочередно выполняются две операции. (1) Как только набор центроидов μk становится доступен, каждый кластер обновляется таким образом, чтобы содержать точки ближайшие к данному центроиду. (2) Как только набор кластеров становится доступен, каждый центроид пересчитывается, как среднее значение всех точек, принадлежащих данному кластеру.
Двухэтапная процедура повторяется, пока кластеры и центроиды не перестанут изменяться. Как уже было сказано, сходимость гарантируется, но решение может представлять собой локальный минимум. На практике, алгоритм выполняется несколько раз, и результаты усредняются. Для получения набора начальных центроидов можно использовать несколько методов, например центроиды можно задать случайным образом.
Ниже представлена простая реализация на Python алгоритма Ллойда для выполнения кластеризации с помощью метода k-средних:
Кластеризация в действии
Давайте рассмотрим алгоритм в действии! В наборе, состоящем из 100 случайных точек на плоскости, с помощью функции k-средних выделим 7 кластеров. Алгоритм сходится за 7 итераций при задании начальных центроидов случайным образом. На расположенных ниже диаграммах точки представляют собой целевые точки из множества X, а звезды – центроиды кластеров μk. Каждый кластер обозначен собственным цветом.
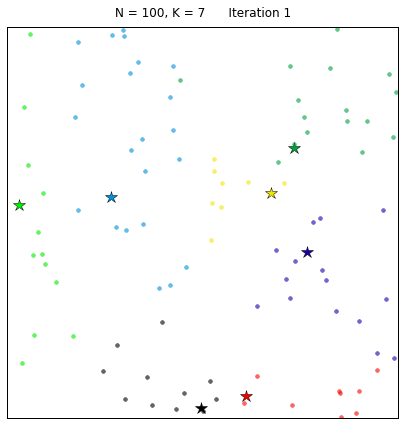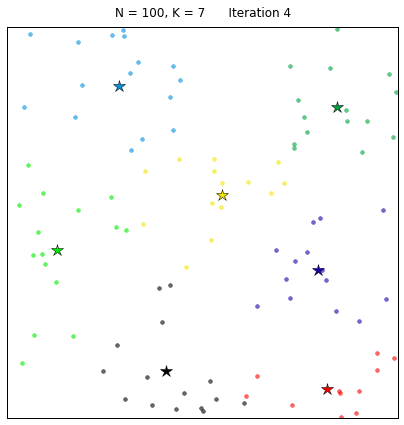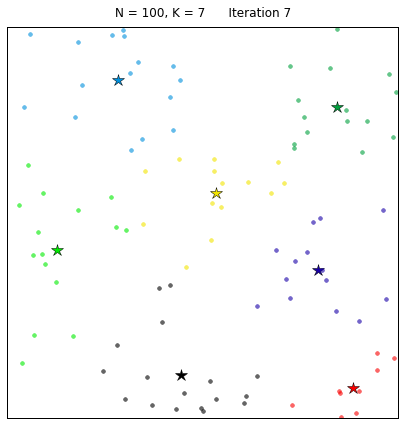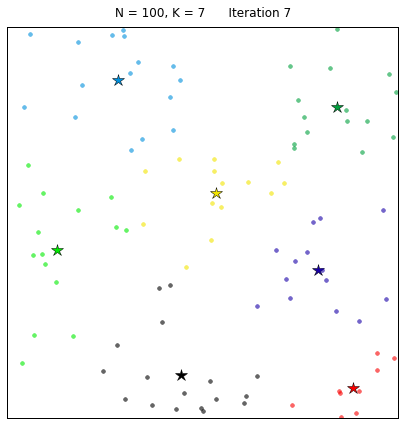
Начальная конфигурация точек для алгоритма получена следующим образом:
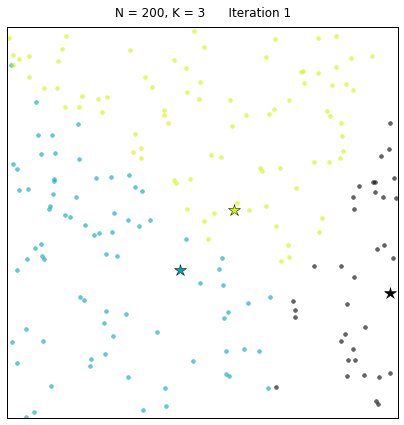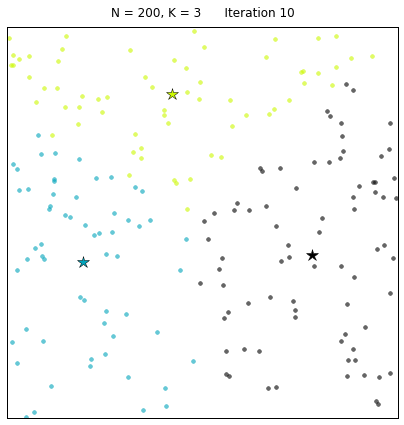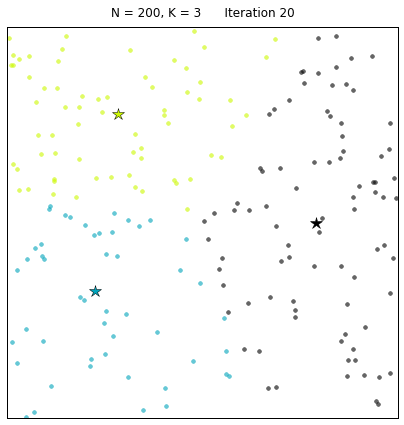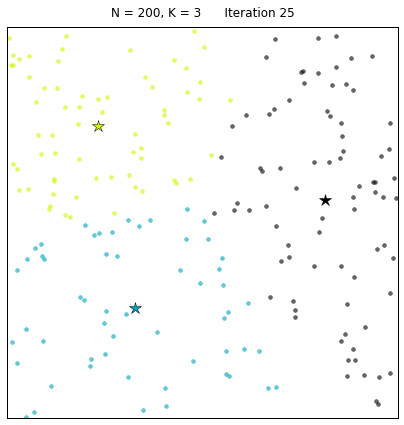
В случае конфигурации с вдвое большим количеством точек и тремя кластерами алгоритму обычно требуется больше итераций, чтобы сойтись.
Очевидно, что набор сгенерированных случайным образом точек не обладает естественной кластерной структурой. С целью немного усложнить задачу, модифицируем функцию, генерирующую исходные точки, чтобы получить более интересную структуру. Следующая функция создает заданное количество кластеров с гауссовским распределением и случайной дисперсией:
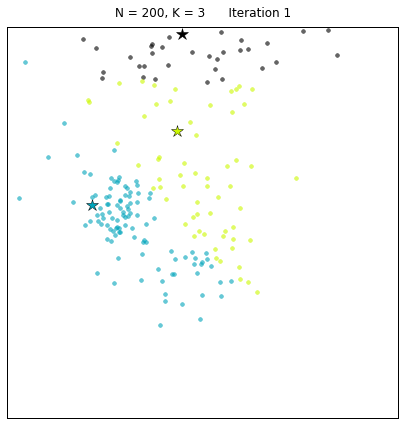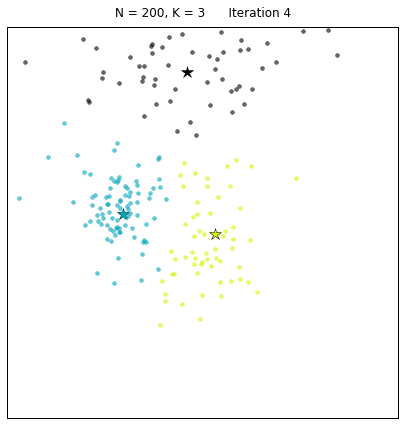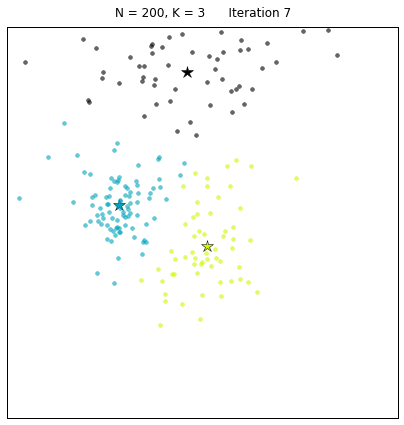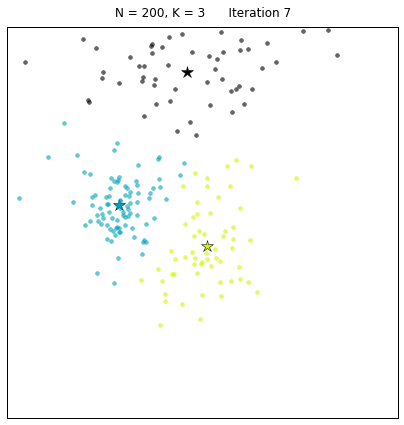
Давайте рассмотрим набор данных, созданный следующим образом: X = init_board_gauss(200, 3). Чтобы найти 3 центроида требуется 7 итераций.
Если целевое распределение имеет разрозненную структуру, и используется только один экземпляр алгоритма Ллойда, возникает опасность того, что полученный локальный минимум не является оптимальным решением. Это показано в примере ниже, где начальные данные имеют островершинное гауссовское распределение:

Желтый и черный центроиды представляют по два различных кластера каждый, в то время как оранжевый, красный и синий центроиды теснятся в пределах одного кластера вследствие неудачной случайной инициализации. В подобных случаях помогает более рациональный выбор начальных кластеров.
Чтобы завершить наш настольный эксперимент по кластеризации с помощью метода k-средних, давайте рассмотрим ситуацию, когда пространство данных плотно заполнено:
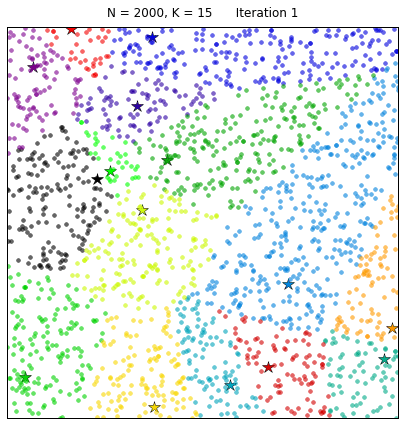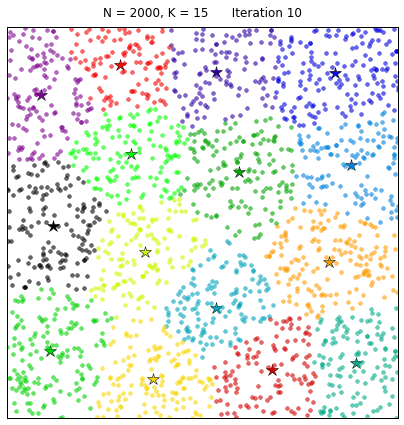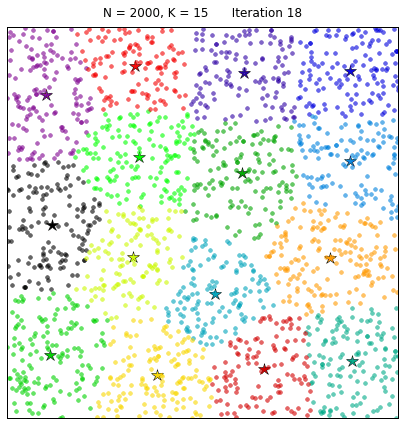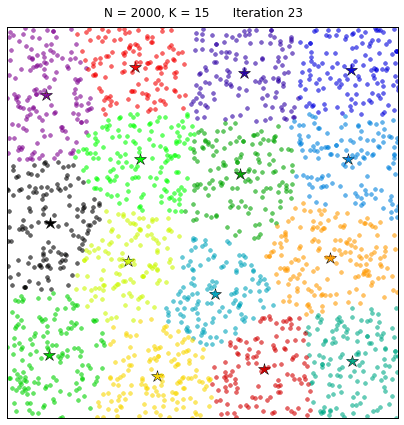
Алгоритм k-средних разделяет данные подобно диаграмме Вороного, полученной на основе K центроидов. И это, безусловно, очень красиво!
Список источников
- datareview.info









