Расчет силуэта
В этом разделе мы узнаем, как рассчитать оценку силуэта.
Оценка силуэта может быть рассчитана по следующей формуле:
силуэтсчет=fracleft(pqright)maxleft(p,qright)
Здесь ???? – среднее расстояние до точек в ближайшем кластере, частью которых точка данных не является. И, ???? – среднее расстояние внутри кластера до всех точек его собственного кластера.
Чтобы найти оптимальное количество кластеров, нам нужно снова запустить алгоритм кластеризации, импортировав модуль метрик из пакета sklearn . В следующем примере мы запустим алгоритм кластеризации K-средних, чтобы найти оптимальное количество кластеров:
Импортируйте необходимые пакеты, как показано на рисунке –
import matplotlib.pyplot as plt import seaborn as sns; sns.set()import numpy as np from sklearn.cluster importKMeans
С помощью следующего кода мы сгенерируем двумерный набор данных, содержащий четыре больших объекта, используя make_blob из пакета sklearn.dataset .
from sklearn.datasets.samples_generator import make_blobs X, y_true = make_blobs(n_samples =500, centers =4, cluster_std =0.40, random_state =)
Инициализируйте переменные как показано –
scores =[] values = np.arange(2,10)
Нам нужно пройти через модель K-средних по всем значениям, а также обучить ее входным данным.
for num_clusters in values kmeans =KMeans(init ='k-means++', n_clusters = num_clusters, n_init =10) kmeans.fit(X)
Теперь оцените оценку силуэта для текущей модели кластеризации, используя евклидову метрику расстояния –
score = metrics.silhouette_score(X, kmeans.labels_, metric ='euclidean', sample_size = len(X))
Следующая строка кода поможет в отображении количества кластеров, а также показателя Силуэт.
print("\nNumber of clusters =", num_clusters)print("Silhouette score =", score)
scores.append(score)
Вы получите следующий вывод –
Number of clusters = 9
Silhouette score = 0.340391138371
num_clusters = np.argmax(scores) + values
print('\nOptimal number of clusters =', num_clusters)
Теперь вывод для оптимального количества кластеров будет следующим:
Optimal number of clusters = 2
Что такое кластеризация?
По сути, это тип неконтролируемого метода обучения и распространенный метод статистического анализа данных, используемый во многих областях. Кластеризация главным образом является задачей разделения набора наблюдений на подмножества, называемые кластерами, таким образом, чтобы наблюдения в одном и том же кластере были похожи в одном смысле и не похожи на наблюдения в других кластерах. Проще говоря, мы можем сказать, что главная цель кластеризации – группировать данные на основе сходства и различий.
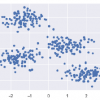
Например, следующая диаграмма показывает аналогичные данные в разных кластерах –
Список источников
- coderlessons.com