Реализация в Python
Следующие два примера реализации алгоритма кластеризации K-Means помогут нам в его лучшем понимании:
Пример 1
Это простой пример, чтобы понять, как работает k-means. В этом примере мы сначала сгенерируем 2D-набор данных, содержащий 4 разных больших объекта, а затем применим алгоритм k-средних, чтобы увидеть результат.
Сначала мы начнем с импорта необходимых пакетов –
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans
Следующий код сгенерирует 2D, содержащий четыре капли:
from sklearn.datasets.samples_generator import make_blobs X, y_true = make_blobs(n_samples = 400, centers = 4, cluster_std = 0.60, random_state = 0)
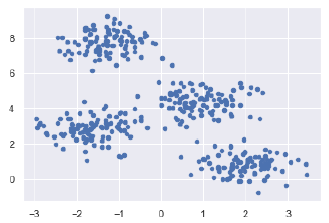
Далее, следующий код поможет нам визуализировать набор данных –
plt.scatter(X, X, s = 20); plt.show()
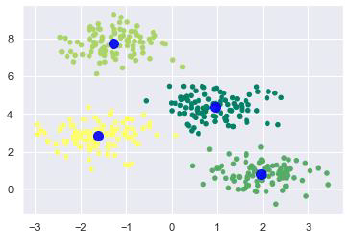
Затем создайте объект KMeans вместе с указанием количества кластеров, обучите модель и сделайте прогноз следующим образом:
kmeans = KMeans(n_clusters = 4) kmeans.fit(X) y_kmeans = kmeans.predict(X)
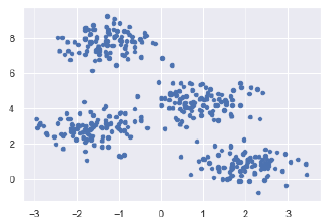
Теперь с помощью следующего кода мы можем построить и визуализировать центры кластера, выбранные с помощью k-средних оценки Python –
from sklearn.datasets.samples_generator import make_blobs X, y_true = make_blobs(n_samples = 400, centers = 4, cluster_std = 0.60, random_state = 0)
Далее, следующий код поможет нам визуализировать набор данных –
plt.scatter(X, X, c = y_kmeans, s = 20, cmap = 'summer') centers = kmeans.cluster_centers_ plt.scatter(centers, centers, c = 'blue', s = 100, alpha = 0.9); plt.show()
Пример 2
Давайте перейдем к другому примеру, в котором мы собираемся применить кластеризацию K-средних к набору простых цифр. K-means попытается идентифицировать похожие цифры, не используя информацию оригинальной этикетки.
Сначала мы начнем с импорта необходимых пакетов –
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans
Затем загрузите набор цифр из sklearn и создайте из него объект. Мы также можем найти количество строк и столбцов в этом наборе данных следующим образом:
from sklearn.datasets import load_digits digits = load_digits() digits.data.shape
(1797, 64)
Приведенный выше вывод показывает, что этот набор данных имеет 1797 выборок с 64 признаками.
Мы можем выполнить кластеризацию, как в примере 1 выше –
kmeans = KMeans(n_clusters = 10, random_state = 0) clusters = kmeans.fit_predict(digits.data) kmeans.cluster_centers_.shape
(10, 64)
Приведенный выше вывод показывает, что K-means создал 10 кластеров с 64 функциями.
fig, ax = plt.subplots(2, 5, figsize=(8, 3)) centers = kmeans.cluster_centers_.reshape(10, 8, 8) for axi, center in zip(ax.flat, centers): axi.set(xticks=[], yticks=[]) axi.imshow(center, interpolation='nearest', cmap=plt.cm.binary)
В качестве результата мы получим следующее изображение, показывающее центры кластеров, изученные с помощью k-средних.
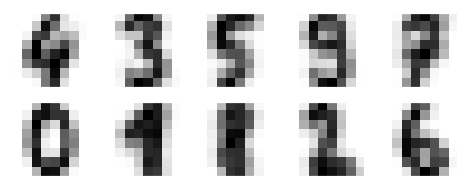
Следующие строки кода будут сопоставлять изученные метки кластера с истинными метками, найденными в них:
from scipy.stats import mode labels = np.zeros_like(clusters)for i in range(10): mask =(clusters == i) labelsmask= mode(digits.targetmask])[
Далее мы можем проверить точность следующим образом:
from sklearn.metrics import accuracy_score accuracy_score(digits.target, labels)
Сравнение сервисов
В поиске самых популярных сервисов очень помог доклад Александра Ожгибесова на BDD-2017, к тем, что у него было добавлено еще несколько сервисов, получился такой список:
- Топвизор
- Pixelplus
- Serpstat
- Rush Analytics
- Just Magic
- Key Collector
- MindSerp
- Semparser
- KeyAssort
- coolakov.ru
Первое на что проверялись полученные в результате кластеризации эталонного ядра по этим сервисам группы – это не делает ли сервис слишком широкие группы. А именно не попали ли запросы из разных групп эталонного ядра в один кластер по версии сервиса.
Но только такого сравнения не достаточно. Сервисы делятся на два подхода к некластеризованному остатку фраз:
- сделать для них общую группу «Некластеризованные»;
- сделать для каждой некластеризованной фразы группу из нее одной.
В сравнении я использовал оба этих параметра в виде соотношения – какой процент фраз от общего количества попал не в свою группу.
Результаты сравнения:
- Топвизор
- разные группы эталона в одной по сервису – 4%
- одна группа эталона в разных по сервису – 7%
- Pixelplus
- разные группы эталона в одной по сервису – 0%
- одна группа эталона в разных по сервису – 7%
- Serpstat
- разные группы эталона в одной по сервису – 0%
- одна группа эталона в разных по сервису – 3%
- Rush Analytics (132 фразы, demo)
- разные группы эталона в одной по сервису – 11%
- одна группа эталона в разных по сервису – 8%
- Just Magic
- разные группы эталона в одной по сервису – 0%
- одна группа эталона в разных по сервису – 9%
- Key Collector
- разные группы эталона в одной по сервису – 12%
- одна группа эталона в разных по сервису – 16%
- MindSerp – не удалось получить демо, не выходят на связь
- Semparser
- разные группы эталона в одной по сервису – 1%
- одна группа эталона в разных по сервису – 3%
- KeyAssort
- разные группы эталона в одной по сервису – 1%
- одна группа эталона в разных по сервису – 1%
- coolakov.ru
- разные группы эталона в одной по сервису – 0%
- одна группа эталона в разных по сервису – 18%
Сравнение[править]
Не существует лучшего метода оценки качества кластеризации. Однако, в рамках исследования была предпринята попытка сравнить существующие меры на различных данных. Полученные результаты показали, что на искусственных датасетах наилучшим образом себя проявили индексы , и . На реальных датасетах лучше всех показал себя .
В Таблице 1 приведены оценки сложности мер качества кластеризации ( — число объектов в рассматриваемом наборе данных):
Из всех рассмотренных мер, меры , , и наиболее полно соответствуют когнитивному представлению асессоров о качестве кластеризации.
Создание кластерных ролейCreate clustered roles
После создания отказоустойчивого кластера можно создать кластерные роли для размещения кластерных рабочих нагрузок.After you create the failover cluster, you can create clustered roles to host cluster workloads.
Примечание
Для кластерных ролей, требующих точки доступа клиента, в доменных службах Active Directory создается виртуальный объект-компьютер (VCO).For clustered roles that require a client access point, a virtual computer object (VCO) is created in AD DS. По умолчанию все объекты VCO для кластера создаются в том же контейнере или подразделении, что и объект CNO.By default, all VCOs for the cluster are created in the same container or OU as the CNO. Имейте в виду, что после создания кластера объект CNO можно переместить в любое подразделение.Realize that after you create a cluster, you can move the CNO to any OU.
Вот как можно создать кластерную роль:Here’s how to create a clustered role:
-
Чтобы на каждом узле отказоустойчивого кластера установить роль или компонент, необходимый для кластерной роли, используйте диспетчер сервера или Windows PowerShell.Use Server Manager or Windows PowerShell to install the role or feature that is required for a clustered role on each failover cluster node. Например, чтобы создать кластерный файловый сервер, установите роль файлового сервера на всех узлах кластера.For example, if you want to create a clustered file server, install the File Server role on all cluster nodes.
В таблице ниже приведены кластерные роли, которые можно настроить в мастере высокой доступности, и соответствующие роли или компоненты сервера, которые необходимо установить.The following table shows the clustered roles that you can configure in the High Availability Wizard and the associated server role or feature that you must install as a prerequisite.
Кластерная рольClustered Role Необходимая роль или компонентRole or Feature Prerequisite Сервер пространства именNamespace Server Пространства имен (часть роли файлового сервера)Namespaces (part of File Server role) Сервер пространства имен DFSDFS Namespace Server Роль DHCP-сервераDHCP Server role Координатор распределенных транзакций (DTC)Distributed Transaction Coordinator (DTC) НетNone Файловый серверFile Server Роль файлового сервераFile Server role Универсальное приложениеGeneric Application Не применимоNot applicable Универсальный сценарийGeneric Script Не применимоNot applicable Универсальная службаGeneric Service Не применимоNot applicable Брокер реплики Hyper-VHyper-V Replica Broker Роль Hyper-VHyper-V role Сервер цели iSCSIiSCSI Target Server Сервер цели iSCSI (часть роли файлового сервера)iSCSI Target Server (part of File Server role) iSNS-серверiSNS Server Компоненты службы iSNS-сервераiSNS Server Service feature Очередь сообщенийMessage Queuing Компонент службы очереди сообщенийMessage Queuing Services feature Другой серверOther Server НетNone Виртуальная машинаVirtual Machine Роль Hyper-VHyper-V role WINS-серверWINS Server Компонент WINS-сервераWINS Server feature -
В диспетчер отказоустойчивости кластеров разверните узел имя кластера, щелкните правой кнопкой мыши элемент ролии выберите пункт настроить роль.In Failover Cluster Manager, expand the cluster name, right-click Roles, and then select Configure Role.
-
Для создания кластерной роли выполните последовательность действий, предлагаемую мастером высокой доступности.Follow the steps in the High Availability Wizard to create the clustered role.
-
Чтобы проверить, создана ли кластерная роль, на панели Роли убедитесь в том, что роль имеет состояние Выполняется.To verify that the clustered role was created, in the Roles pane, make sure that the role has a status of Running. На панели “Роли” также указан узел владельца.The Roles pane also indicates the owner node. Чтобы протестировать отработку отказа, щелкните правой кнопкой мыши роль, выберите пункт переместить, а затем выберите пункт выбрать узел.To test failover, right-click the role, point to Move, and then select Select Node. В диалоговом окне Перемещение кластерной роли выберите нужный узел кластера и нажмите кнопку ОК.In the Move Clustered Role dialog box, select the desired cluster node, and then select OK. В столбце Узел владельца убедитесь в том, что узел владельца изменился.In the Owner Node column, verify that the owner node changed.
Преимущества и недостатки
преимущества
Ниже приведены некоторые преимущества алгоритмов кластеризации K-Means:
-
Это очень легко понять и реализовать.
-
Если у нас будет большое количество переменных, тогда K-means будет быстрее, чем иерархическая кластеризация.
-
При повторном вычислении центроидов экземпляр может изменить кластер.
-
Более плотные кластеры формируются с помощью K-средних по сравнению с иерархической кластеризацией.
Это очень легко понять и реализовать.
Если у нас будет большое количество переменных, тогда K-means будет быстрее, чем иерархическая кластеризация.
При повторном вычислении центроидов экземпляр может изменить кластер.
Более плотные кластеры формируются с помощью K-средних по сравнению с иерархической кластеризацией.
Недостатки
Ниже приведены некоторые недостатки алгоритмов кластеризации K-Means:
-
Немного сложно предсказать количество кластеров, то есть значение k.
-
На выход сильно влияют исходные данные, такие как количество кластеров (значение k)
-
Порядок данных будет иметь сильное влияние на конечный результат.
-
Это очень чувствительно к масштабированию. Если мы будем масштабировать наши данные с помощью нормализации или стандартизации, то вывод полностью изменится.
-
В кластеризации плохо работать, если кластеры имеют сложную геометрическую форму.
Немного сложно предсказать количество кластеров, то есть значение k.
На выход сильно влияют исходные данные, такие как количество кластеров (значение k)
Порядок данных будет иметь сильное влияние на конечный результат.
Это очень чувствительно к масштабированию. Если мы будем масштабировать наши данные с помощью нормализации или стандартизации, то вывод полностью изменится.
В кластеризации плохо работать, если кластеры имеют сложную геометрическую форму.
Методика сравнения
Суть сравнения сервисов в следующем: выбрать идеально кластеризованный список запросов – эталонное ядро. Сравнить результаты кластеризации каждого сервиса с эталонным.
Важно было хорошо составить такое эталонное ядро. Поскольку у нас контентный проект и большая часть контента – это вопросы и ответы пользователей, то материала для сбора статистики по проекту предостаточно
Было взято ядро на 2500+ ключевых фраз, которое отслеживается уже много месяцев. Из него выбраны только запросы вышедшие в топ-5 Яндекса. И из них взяты только те которые имеют релевантной страницу одного из широких разделов (категория вопроса, тема вопроса, категория документа, страница с формой «задать вопрос»), а не узкую страницу вопроса с ответами. Запросы были сгруппированы по релевантной странице. Оставлены только группы в которых более чем 4 запроса. В итоге получилось 292 запроса разбитых на 22 кластера.
Забегая вперед скажу, что сравнивались результаты кластеризации по Московской выдаче Яндекса и без геопривязки. Региональная московская выдача показала себя лучше, поэтому далее будем говорить про нее.
Зачем нужны сервисы кластеризации?
В один кластер должны быть объединены только такие запросы, которые имеют хорошие шансы выйти в топ-10 поисковых систем с общей релевантной страницей. То есть, если по двум запросам в выдаче все страницы сайтов разные и нет пересечений, то следует относить их к разным кластерам. Также и наоборот: если два запроса возможно продвинуть на одной статье, то не следует разносить их на разные кластеры, чтобы не писать лишнего – бюджет на контент не резиновый.
Общая схема составления ТЗ на написание SEO-статьи следующая:
Сбор семантики – статистика поисковых систем, базы семантики, внутренняя статистика проекта;
Кластеризация автоматическая – сервис или программа для кластеризации по подобию топов;
«Посткластеризация» ручная – обработка того что не удалось кластеризовать автоматически;
Приоритезация – определение важности полученных запросов в каждом кластере;
Оформление ТЗ для копирайтера – лемматизация, LSI и различные указания для написания статей, по статье на каждый кластер.
Вот именно для второго пункта нужно было выбрать самый подходящий сервис автоматической кластеризации. Для этой цели я провел сравнительный анализ самых известных, на мой взгляд, сервисов.
Работа алгоритма K-средних
Мы можем понять работу алгоритма кластеризации K-Means с помощью следующих шагов:
Шаг 1 – Во-первых, нам нужно указать количество кластеров, K, которые должны быть сгенерированы этим алгоритмом.
Шаг 2 – Затем случайным образом выберите K точек данных и назначьте каждую точку данных кластеру. Проще говоря, классифицировать данные на основе количества точек данных.
Шаг 3 – Теперь он будет вычислять кластерные центроиды.
Шаг 4 – Далее, продолжайте повторять следующее до тех пор, пока мы не найдем оптимальный центроид, который является назначением точек данных кластерам, которые больше не меняются
-
4.1 – Сначала будет вычислена сумма квадратов расстояния между точками данных и центроидами.
-
4.2 – Теперь мы должны назначить каждую точку данных кластеру, который находится ближе, чем другой кластер (центроид).
-
4.3 – Наконец, вычислите центроиды для кластеров, взяв среднее значение всех точек данных этого кластера.
4.1 – Сначала будет вычислена сумма квадратов расстояния между точками данных и центроидами.
4.2 – Теперь мы должны назначить каждую точку данных кластеру, который находится ближе, чем другой кластер (центроид).
4.3 – Наконец, вычислите центроиды для кластеров, взяв среднее значение всех точек данных этого кластера.
K-означает следовать подходу ожидания-максимизации для решения проблемы. Шаг ожидания используется для назначения точек данных ближайшему кластеру, а шаг максимизации используется для вычисления центроида каждого кластера.
При работе с алгоритмом K-means мы должны позаботиться о следующих вещах:
-
При работе с алгоритмами кластеризации, включая K-Means, рекомендуется стандартизировать данные, поскольку такие алгоритмы используют измерения на основе расстояний для определения сходства между точками данных.
-
Из-за итеративной природы K-средних и случайной инициализации центроидов K-средние могут придерживаться локального оптимума и могут не сходиться к глобальному оптимуму. Вот почему рекомендуется использовать разные инициализации центроидов.
При работе с алгоритмами кластеризации, включая K-Means, рекомендуется стандартизировать данные, поскольку такие алгоритмы используют измерения на основе расстояний для определения сходства между точками данных.
Из-за итеративной природы K-средних и случайной инициализации центроидов K-средние могут придерживаться локального оптимума и могут не сходиться к глобальному оптимуму. Вот почему рекомендуется использовать разные инициализации центроидов.
Список источников
- docs.microsoft.com










