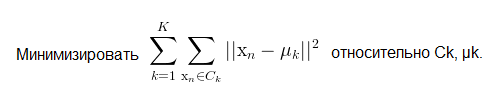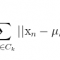Выбор способа кластеризации
Для кластеризации данных в RapidMiner был выбран наиболее распространённый среди неиерархических методов алгоритм k-средних, также называемый быстрым кластерным анализом. Принцип работы алгоритма был кратко нами рассмотрен в четвёртом разделе второй главы.
Рис. 5.3. Цепочка узлов решения поставленной задачи
Перечислим основные достоинства и недостатки данного алгоритма.
Достоинства:
Ё простота использования;
Ё быстрота использования;
Ё понятность и прозрачность алгоритма.
Недостатки:
Ё слишком чувствителен к выбросам;
Ё может медленно работать на больших базах данных;
Ё не в состоянии выбрать автоматически оптимальное число кластеров.
Оценка качества кластеризации
Для решения последней проблемы в предыдущем разделе, в среде RapidMiner был разработан новый процесс, выполняющий оценивание качества кластеризации по двум параметрам, выполненный на основе метода k-средних путём перебора различного числа кластеров. Дополнительно в процесс был включён оператор валидации.
Рис. 5.4. Общий вид процесса оценки качества кластеризации
Здесь оператор «Loop Parameters» представляет из себя совокупность функций и подпроцессов по оценке качества кластеризации на основе алгоритма k-means:
Рис. 5.5. Состав оператора «Loop Parameters»
Краткое описание операторов:
Ё «Multiply» – создаёт копию входных данных на выходе;
Ё «Clustering» – процесс кластеризации алгоритмом k-means;
Ё «Distance» – оценивает среднее расстояние между кластерами путём вычисления среднего расстояния между центроидами и всеми входными данными кластера.
Ё «Distribution» – оценивает распределение данных по кластерам.
Рис. 5.6. Задание параметров в операторе «Loop Parameters»
Валидация кластеров. Под валидацией кластеров понимают проверку их обоснованности. Различают два типа валидации: внутреннюю – по тому, насколько кластеры соответствуют данным, и внешнюю – по тому, насколько кластеры соответствуют информации, не учитывавшейся при их построении, но известной специалистам – такого рода информация обычно представляется в виде разбиения.
Среди многообразия различных индексов, использующихся для валидации кластеров, наиболее популярным является индекс – Дэвиса Болдина, который можно определить следующим образом. Охарактеризуем относительный разброс в двух кластерах как полусумму средних расстояний их элементов до центров, делённую на расстояние между центрами. Охарактеризуем разброс кластера максимальной величиной его относительного разброса (относительно других кластеров). Тогда индекс Дэвиса – Болдина – не что иное, как средний разброс кластеров.
Результаты всех выполненных вычислений оператором «Loop Parameters» представлены в численном и графическом виде.
Рис. 5.7. Вычисленные значения индексов и параметров
Рис. 5.8. График распределения среднего расстояния между кластерами
Рис. 5.9. График распределения индекса Дэвиса – Болдина
Рис. 5.10. График распределения данных по кластерам
Рис. 5.11. Объединение предыдущих трёх графиков
Проведя анализ полученных графиков, мы пришли к выводу, что значение k = 6, является оптимальным числом для выделения кластеров в наших данных. Это подтверждается двумя известными эмпирическими правилами выбора числа кластеров:
Ё Двух или трёх кластеров, как правило, недостаточно: кластеризация будет слишком грубой, приводящей к потере информации об индивидуальных свойствах объектов.
Ё Больше десяти кластеров не укладывается в «число Миллера 7 ± 2» В 1956 г. Дж. Миллер обобщил имевшиеся данные об объёме кратковременной памяти человека и показал, что этот объём определяется не числом слов в предложении, а числом объектов и обычно равен 7 ± 2.: аналитику трудно держать в кратковременной памяти столько кластеров.
Список источников
- studbooks.net