Сравнение[править]
Не существует лучшего метода оценки качества кластеризации. Однако, в рамках исследования была предпринята попытка сравнить существующие меры на различных данных. Полученные результаты показали, что на искусственных датасетах наилучшим образом себя проявили индексы , и . На реальных датасетах лучше всех показал себя .
В Таблице 1 приведены оценки сложности мер качества кластеризации ( — число объектов в рассматриваемом наборе данных):
Из всех рассмотренных мер, меры , , и наиболее полно соответствуют когнитивному представлению асессоров о качестве кластеризации.
Преимущества и недостатки
преимущества
Ниже приведены некоторые преимущества алгоритмов кластеризации K-Means:
-
Это очень легко понять и реализовать.
-
Если у нас будет большое количество переменных, тогда K-means будет быстрее, чем иерархическая кластеризация.
-
При повторном вычислении центроидов экземпляр может изменить кластер.
-
Более плотные кластеры формируются с помощью K-средних по сравнению с иерархической кластеризацией.
Это очень легко понять и реализовать.
Если у нас будет большое количество переменных, тогда K-means будет быстрее, чем иерархическая кластеризация.
При повторном вычислении центроидов экземпляр может изменить кластер.
Более плотные кластеры формируются с помощью K-средних по сравнению с иерархической кластеризацией.
Недостатки
Ниже приведены некоторые недостатки алгоритмов кластеризации K-Means:
-
Немного сложно предсказать количество кластеров, то есть значение k.
-
На выход сильно влияют исходные данные, такие как количество кластеров (значение k)
-
Порядок данных будет иметь сильное влияние на конечный результат.
-
Это очень чувствительно к масштабированию. Если мы будем масштабировать наши данные с помощью нормализации или стандартизации, то вывод полностью изменится.
-
В кластеризации плохо работать, если кластеры имеют сложную геометрическую форму.
Немного сложно предсказать количество кластеров, то есть значение k.
На выход сильно влияют исходные данные, такие как количество кластеров (значение k)
Порядок данных будет иметь сильное влияние на конечный результат.
Это очень чувствительно к масштабированию. Если мы будем масштабировать наши данные с помощью нормализации или стандартизации, то вывод полностью изменится.
В кластеризации плохо работать, если кластеры имеют сложную геометрическую форму.
Метод 2: Кластеризация
Основная идея — найти группы клиентов без использования предварительных гипотез о структуре клиентской базы, найти натуральные кластеры среди свойств клиентов исходя из имеющихся данных.
Существует набор методов (K-mean, C-mean, иерархическая кластеризация и т.п.), которые позволяют вам определить близость объектов друг друга на основании их свойств. В общем случае вы описываете вашего клиента как вектор, каждый элемент этого вектора описывает какую-то характеристику клиента (будь то выручка, кол-во месяцев сотрудничества, адрес регистрации, купленные продукты и т.п.). После чего вы преобразуете этот вектор в нужный формат для вашего алгоритма, натравливаете алгоритм на данные (и настраиваете его для кластеризации) и получаете на выходе разделение клиентов на кластеры.
Хотя процесс не выглядит сложным, детали методов и их интерпретация имеет большое значение. Выбранные метрики “расстояния”, способ трансформации данных и кол-во выбранных факторов могут сильно менять картину. Так как в конечном итоге в многомерных данных нет однозначно “правильного” решения задачи кластеризации, вам в конечном итоге придется самостоятельно оценивать качество кластеров, а именно в итоге искать для них “бизнес” интерпретацию, если вы собрались использовать эти кластеры в принятии решений людьми.
По опыту могу сказать, что не стоит использовать сложные и логически не связанные свойства клиентов, а также хитрые трансформации. Несмотря на вероятные, элегантные решения по линии алгоритмов на выходе вы можете получить сложно интерпретируемые кластеры, которые ничего вам не надут в бизнес контексте. Возможно ваш метод и хорош, если кластера будут использоваться для входных параметров другой системы машинного обучения. Но когда вы хотите разделить клиентскую базу и сформулировать маркетинговую стратегию, то такие хитрые кластера вас никуда не приведут.
Сам процесс кластеризации это итеративный процесс:
- Составьте вектор
- Трансформируйте данные
- Настройте параметры алгоритма
- Сделайте кластеризацию
- Оцените кластеры экспертно, можете ли вы их использовать
- Повторите п.1., если кластеры вас не удовлетворили
Преимущество этого подхода, что через множество итераций вы куда лучше будете понимать ваших клиентов и данных о них, т.к. Каждая попытка кластеризации покажет вам разрез поведения и свойств клиентов, на который вы никогда скорее всего не смотрели. Вы так же лучше поймете взаимосвязи и взаимоотношения между разными клиентами. Поэтому я советую проделать это упражнение и вывести свои собственные кластеры.
Прошлый статьи в цикле:
Это 6-ая статья в цикле статей по анализу продукта:
- Top-Down approach. Экономика продукта. Gross Profit
- Экономика продукта. Анализ выручки
- Погружаемся в динамику клиентской базы: когортный анализ и анализ потоков
- Собираем когортный анализ/анализ потоков на примере Excel
- Аналитика воронки продаж
- MPRU, выручка и как это связано с выручкой и динамикой клиентской базы
Алгоритмы и методы балансировки
- справедливость: нужно гарантировать, чтобы на обработку каждого запроса выделялись системные ресурсы и не допустить возникновения ситуаций, когда один запрос обрабатывается, а все остальные ждут своей очереди;
- эффективность: все серверы, которые обрабатывают запросы, должны быть заняты на 100%; желательно не допускать ситуации, когда один из серверов простаивает в ожидании запросов на обработку (сразу же оговоримся, что в реальной практике эта цель достигается далеко не всегда);
- сокращение времени выполнения запроса: нужно обеспечить минимальное время между началом обработки запроса (или его постановкой в очередь на обработку) и его завершения;
- сокращение времени отклика: нужно минимизировать время ответа на запрос пользователя.
- предсказуемость: нужно чётко понимать, в каких ситуациях и при каких нагрузках алгоритм будет эффективным для решения поставленных задач;
- равномерная загрузка ресурсов системы;
- масштабирумость: алгоритм должен сохранять работоспособность при увеличении нагрузки.
Round Robin
example.com xxx.xxx.xxx.2 www.example.com xxx.xxx.xxx.3
example.com xxx.xxx.xxx.2 www.example.com xxx.xxx.xxx.3 www.example.com xxx.xxx.xxx.4 www.example.com xxx.xxx.xxx.5 www.example.com xxx.xxx.xxx.6
Sticky Sessions
upstream backend {
ip_hash;
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
server backend4.example.com;
}
Метод 1: Эвристики и экспертные оценки
В рамках этого подхода вы на основе опыта, логики использования вашего продукта и клиентских историй, придумываете различные портреты потребителей и затем оцениваете, сколько у вас клиентов попадают под эти определения. Или же можете использовать более численные подходы, основанные на анализе показателей клиентов. Несколько популярных численным эвристик подходов это:
ABC-XYZ
Основная идея разделить клиентов по общему вкладу в вашу выручку и по динамике роста показателей. ABC отвечает за вклад в выручку, XYZ отвечает за стабильность выручки. Это формирует 9 сегментов
AX — самые большие и со стабильной выручкой
AZ — Большие, но они редко делают покупки, выручка не стабильна
CX — самые мелкие, но со стабильной выручкой
CZ — мелкие и выручка не стабильна, покупки совершают редко
В сегмент А определяют клиентов, кто формирует 80% выручки, в сегмент B, кто дает еще 15% и в сегмент C, кто дает 5%. В сегмент X — наименьшую вариативность выручки (можно взять 33 перцентиль), Z — наивысшая вариативность (соответственно верхний 33 перцентиль). Под вариативность я подразумеваю величину дисперсии выручки.
Что дает этот анализ: он позволяет разделить ваших клиентов на группы по степени важности для вашего бизнеса. Клиенты из группы AX, AY, AZ самые большие и вы должны уделять им больше всего внимания
Клиенты групп BX, BY требуют дополнительного внимания, их можно развивать
Внимание к группам в других категориях можно снижать. Особенно хорошо, если вам удастся выделить общности между клиентами в разных сегментах, что позволит вам таргетировать усилия по привлечению нужных клиентов
RFM (Recency-Frequency-Money)
Основная идея разделить клиентов по 3-м свойствам: как давно была продажа клиенту (recency), как часто он покупает товары (frequency), какой объем выручки он сгенерировал(money). В целом подход напоминает ABС-XYZ, но несколько под другим углом.
В рамках этого подхода вы разделяете клиентов по группам Recency, например:
- 0-30 дней
- 31-60 дней
- 61-90 дней
- 90+
По кол-ву покупок, например:
- Более 15
- 10-14
- 5-9
- 0-4
По объему выручки:
- 1000+
- 600-1000
- 200-599
- 0-199
Понятно, что для каждого конкретного продукта, приложения или товара вам нужно установить свои границы.
В итоге вы сможете разделить клиентов на множество сегментов, каждый из которых характеризует клиента по степени важности для вас
Матрица BCG
Основная идея разделить клиентов по категориям объема выручки и темпов роста выручки. Такой подход позволяет определить, кто большой и насколько быстро растет. Все клиенты раскладываются на 4 квадранта:
Звезды — крупнейшие клиенты с высоким темпов роста выручки
Это клиенты, кому надо уделять наибольшее внимание. Это сильная точка роста
Дойные коровы — крупные клиенты, с низкими или отрицательными темпами выручки
Эти клиенты будут формировать ядро вашей текущей выручки. Проглядите коров и потеряете бизнес.
Темные лошадки — пока мелкие клиенты, но с большим темпом роста. Это группы клиентов, на кого надо обращать внимание, т.к. они могут вырасти до звезд или дойных коров.
Собаки — мелкие клиенты с низкими или отрицательными темпами роста. Это клиенты, кому можно уделять наименьшее внимание и применять к ним массовые методы обслуживания, для сокращения издержек.
Преимущества всех эвристических методов — относительная простота реализации и возможность разделить своих клиентов на понятные с точки зрения бизнеса группы.
Недостатки в том, что мы используем всего лишь несколько свойств клиентов, для их описания и исключаем из рассмотрения прочие факторы. В добавок, чаще всего клиенты оказываются в сегментах временно, меняют позицию, а установить реальную общность внутри сегмента оказывается сложно.
Задача
Потребность иметь хранилище с данными для почти любого приложения — необходимость. А иметь это хранилище устойчивым к невзгодам в сети или на физических серверах — хороший тон грамотного архитектора. Другой аспект — высокая доступность сервиса даже при больших конкурирующих запросах на обслуживание, что означает легкое масштабирование при необходимости.
Итого получаем проблемы для решения:
- Физически распределенный сервис
- Балансировка
- Не ограниченное масштабирование путем добавление новых узлов
- Автоматическое восстановление при сбоях, уничтожении и потери связи узлами
- Отсутствие единой точки отказа
Дополнительные пункты, обусловленные спецификой религиозных убеждений автора:
- Postgres (наиболее академическое и консистентное решение для РСУБД среди бесплатных доступных)
- Docker упаковка
- Kubernetes описание инфраструктуры
На схеме это будет выглядеть примерно так:
При условии входных данных:
- Большее число запросов на чтение (по отношению к записи)
- Линейный рост нагрузки при пиках до x2 от среднего
Работа алгоритма K-средних
Мы можем понять работу алгоритма кластеризации K-Means с помощью следующих шагов:
Шаг 1 – Во-первых, нам нужно указать количество кластеров, K, которые должны быть сгенерированы этим алгоритмом.
Шаг 2 – Затем случайным образом выберите K точек данных и назначьте каждую точку данных кластеру. Проще говоря, классифицировать данные на основе количества точек данных.
Шаг 3 – Теперь он будет вычислять кластерные центроиды.
Шаг 4 – Далее, продолжайте повторять следующее до тех пор, пока мы не найдем оптимальный центроид, который является назначением точек данных кластерам, которые больше не меняются
-
4.1 – Сначала будет вычислена сумма квадратов расстояния между точками данных и центроидами.
-
4.2 – Теперь мы должны назначить каждую точку данных кластеру, который находится ближе, чем другой кластер (центроид).
-
4.3 – Наконец, вычислите центроиды для кластеров, взяв среднее значение всех точек данных этого кластера.
4.1 – Сначала будет вычислена сумма квадратов расстояния между точками данных и центроидами.
4.2 – Теперь мы должны назначить каждую точку данных кластеру, который находится ближе, чем другой кластер (центроид).
4.3 – Наконец, вычислите центроиды для кластеров, взяв среднее значение всех точек данных этого кластера.
K-означает следовать подходу ожидания-максимизации для решения проблемы. Шаг ожидания используется для назначения точек данных ближайшему кластеру, а шаг максимизации используется для вычисления центроида каждого кластера.
При работе с алгоритмом K-means мы должны позаботиться о следующих вещах:
-
При работе с алгоритмами кластеризации, включая K-Means, рекомендуется стандартизировать данные, поскольку такие алгоритмы используют измерения на основе расстояний для определения сходства между точками данных.
-
Из-за итеративной природы K-средних и случайной инициализации центроидов K-средние могут придерживаться локального оптимума и могут не сходиться к глобальному оптимуму. Вот почему рекомендуется использовать разные инициализации центроидов.
При работе с алгоритмами кластеризации, включая K-Means, рекомендуется стандартизировать данные, поскольку такие алгоритмы используют измерения на основе расстояний для определения сходства между точками данных.
Из-за итеративной природы K-средних и случайной инициализации центроидов K-средние могут придерживаться локального оптимума и могут не сходиться к глобальному оптимуму. Вот почему рекомендуется использовать разные инициализации центроидов.
Реализация в Python
Следующие два примера реализации алгоритма кластеризации K-Means помогут нам в его лучшем понимании:
Пример 1
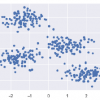
Это простой пример, чтобы понять, как работает k-means. В этом примере мы сначала сгенерируем 2D-набор данных, содержащий 4 разных больших объекта, а затем применим алгоритм k-средних, чтобы увидеть результат.
Сначала мы начнем с импорта необходимых пакетов –
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans
Следующий код сгенерирует 2D, содержащий четыре капли:
from sklearn.datasets.samples_generator import make_blobs X, y_true = make_blobs(n_samples = 400, centers = 4, cluster_std = 0.60, random_state = 0)
Далее, следующий код поможет нам визуализировать набор данных –
plt.scatter(X, X, s = 20); plt.show()
Затем создайте объект KMeans вместе с указанием количества кластеров, обучите модель и сделайте прогноз следующим образом:
kmeans = KMeans(n_clusters = 4) kmeans.fit(X) y_kmeans = kmeans.predict(X)
Теперь с помощью следующего кода мы можем построить и визуализировать центры кластера, выбранные с помощью k-средних оценки Python –
from sklearn.datasets.samples_generator import make_blobs X, y_true = make_blobs(n_samples = 400, centers = 4, cluster_std = 0.60, random_state = 0)
Далее, следующий код поможет нам визуализировать набор данных –
plt.scatter(X, X, c = y_kmeans, s = 20, cmap = 'summer') centers = kmeans.cluster_centers_ plt.scatter(centers, centers, c = 'blue', s = 100, alpha = 0.9); plt.show()
Пример 2
Давайте перейдем к другому примеру, в котором мы собираемся применить кластеризацию K-средних к набору простых цифр. K-means попытается идентифицировать похожие цифры, не используя информацию оригинальной этикетки.
Сначала мы начнем с импорта необходимых пакетов –
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans
Затем загрузите набор цифр из sklearn и создайте из него объект. Мы также можем найти количество строк и столбцов в этом наборе данных следующим образом:
from sklearn.datasets import load_digits digits = load_digits() digits.data.shape
(1797, 64)
Приведенный выше вывод показывает, что этот набор данных имеет 1797 выборок с 64 признаками.
Мы можем выполнить кластеризацию, как в примере 1 выше –
kmeans = KMeans(n_clusters = 10, random_state = 0) clusters = kmeans.fit_predict(digits.data) kmeans.cluster_centers_.shape
(10, 64)
Приведенный выше вывод показывает, что K-means создал 10 кластеров с 64 функциями.
fig, ax = plt.subplots(2, 5, figsize=(8, 3)) centers = kmeans.cluster_centers_.reshape(10, 8, 8) for axi, center in zip(ax.flat, centers): axi.set(xticks=[], yticks=[]) axi.imshow(center, interpolation='nearest', cmap=plt.cm.binary)
В качестве результата мы получим следующее изображение, показывающее центры кластеров, изученные с помощью k-средних.
Следующие строки кода будут сопоставлять изученные метки кластера с истинными метками, найденными в них:
from scipy.stats import mode labels = np.zeros_like(clusters)for i in range(10): mask =(clusters == i) labelsmask= mode(digits.targetmask])[
Далее мы можем проверить точность следующим образом:
from sklearn.metrics import accuracy_score accuracy_score(digits.target, labels)
Уровни балансировки
- сетевому;
- транспортному;
- прикладному.
Балансировка на сетевом уровне
- DNS-балансировка. На одно доменное имя выделяется несколько IP-адресов. Сервер, на который будет направлен клиентский запрос, обычно определяется с помощью алгоритма Round Robin (о методах и алгоритмах балансировки будет подробно рассказано ниже).
- Построение NLB-кластера. При использовании этого способа серверы объединяются в кластер, состоящий из входных и вычислительных узлов. Распределение нагрузки осуществляется при помощи специального алгоритма. Используется в решениях от компании Microsoft.
- Балансировка по IP с использованием дополнительного маршрутизатора.
Внешние меры оценки качества[править]
Данные меры используют дополнительные знания о кластеризуемом множестве: распределение по кластерам, количество кластеров и т.д.
Обозначенияправить
Дано множество из элементов, разделение на классы , и полученное разделение на кластеры , совпадения между и могут быть отражены в таблице сопряженности , где каждое обозначает число объектов, входящих как в , так и в : .
Пусть .
Также рассмотрим пары из элементов кластеризуемого множества . Подсчитаем количество пар, в которых:
- Элементы принадлежат одному кластеру и одному классу —
- Элементы принадлежат одному кластеру, но разным классам —
- Элементы принадлежат разным кластерам, но одному классу —
- Элементы принадлежат разным кластерам и разным классам —
Индекс Randправить
Индекс Rand оценивает, насколько много из тех пар элементов, которые находились в одном классе, и тех пар элементов, которые находились в разных классах, сохранили это состояние после кластеризации алгоритмом.
Имеет область определения от 0 до 1, где 1 — полное совпадение кластеров с заданными классами, а 0 — отсутствие совпадений.
Индекс Adjusted Randправить
где — значения из таблицы сопряженности.
В отличие от обычного , индекс Adjusted Rand может принимать отрицательные значения, если .
Индекс Жаккара (англ. Jaccard Index)править
Индекс Жаккара похож на , только не учитывает пары элементов находящиеся в разные классах и разных кластерах ().
Имеет область определения от 0 до 1, где 1 — полное совпадение кластеров с заданными классами, а 0 — отсутствие совпадений.
Индекс Фоулкса – Мэллова (англ. Fowlkes-Mallows Index)править
Индекс Фоулкса – Мэллова используется для определения сходства между двумя кластерами.
Более высокое значение индекса означает большее сходство между кластерами. Этот индекс также хорошо работает на зашумленных данных.
Hubert Г statisticправить
Данная мера отражает среднее расстояние между объектами разных кластеров:
где , — матрица близости, а
Можно заметить, что два объекта влияют на , только если они находятся в разных кластерах.
Чем больше значение меры — тем лучше.
Entropyправить
Энтропия измеряет “чистоту” меток классов:
Стоит отметить, что если все кластера состоят из объектов одного класса, то энтропия равна 0.
Purityправить
Чистота ставит в соответствие кластеру самый многочисленный в этом кластере класс.
Чистота находится в интервале , причём значение = 1 отвечает оптимальной кластеризации.
Решение методом “Гугления”
Будучи, искушенным в решении IT проблем, человеком, я решил спросить у коллективного разума: “postgres cluster kubernetes” — куча мусора, “postgres cluster docker” — куча мусора, “postgres cluster” — несколько вариантов, из которых пришлось воять.
Что меня расстроило, так это отсутствие вменяемых Docker сборок и описание любого варианта для кластеризации. Не говоря уже о Kubernetes. Кстати говоря, для Mysql вариантов было не много, но все же были. Как минимум понравился пример в официальном репозитории k8s для Galera(Mysql cluster)
Гугл дал ясно понять, что проблемы придется решать самому и в ручном режиме…”но хоть с помощью разрозненных советов и статей” — выдохнул я.
Плохие и непреемлимые решения
Сразу замечу, что все пункты в этом параграфе могут быть субъективными и, вполне даже, жизнеспособными. Однако, полагаясь на свой опыт и чутье, мне пришлось их отсечь.
Список источников
- habr.com
- neerc.ifmo.ru
- coderlessons.com