Методика сравнения
Суть сравнения сервисов в следующем: выбрать идеально кластеризованный список запросов – эталонное ядро. Сравнить результаты кластеризации каждого сервиса с эталонным.
Важно было хорошо составить такое эталонное ядро. Поскольку у нас контентный проект и большая часть контента – это вопросы и ответы пользователей, то материала для сбора статистики по проекту предостаточно
Было взято ядро на 2500+ ключевых фраз, которое отслеживается уже много месяцев. Из него выбраны только запросы вышедшие в топ-5 Яндекса. И из них взяты только те которые имеют релевантной страницу одного из широких разделов (категория вопроса, тема вопроса, категория документа, страница с формой «задать вопрос»), а не узкую страницу вопроса с ответами. Запросы были сгруппированы по релевантной странице. Оставлены только группы в которых более чем 4 запроса. В итоге получилось 292 запроса разбитых на 22 кластера.
Забегая вперед скажу, что сравнивались результаты кластеризации по Московской выдаче Яндекса и без геопривязки. Региональная московская выдача показала себя лучше, поэтому далее будем говорить про нее.
Рекламные записи
Молодой рыбинский врач-эндоскопист с совершенно атрофированным честолюбием вытащил из полыньи провалившегося рыбака, который уже потерял все силы. Сам врач промок, но поехал в больницу принимать пациентов. Никому об этом не рассказал.
Лишь позже жена провалившегося рыбака поведала всем о геройском поступке врача в одном из местных сообществ. Так слава настигла героя:
https://yarportal.ru/topic931843.html?view=findpost&p=32998482
151
ER 0.2846
Внимание! Розыск!
Выехал на Блаблакаре и пропал:
https://yarportal.ru/topic930745.html?view=findpost&p=32917477
111
ER 0.2744
Здравствуйте! Разместите, пожалуйста, информацию????????????
Уважаемые доноры!????????????
СРОЧНО на 31.01.2020 г. Нужна кровь 1- (первая отрицательная) на на тромбоцитарную массу, для Калинина Андрея Александровича (диагноз: острый лейкоз). В данный момент он находится на лечении в Ярославской областной больнице, отделение гематологии. Кровь можно сдать на станции переливания крови по адресу: Тутаевское шоссе, 95в к 8.00. Заявка от врача на 31.01.2020 г (пятница). Доноры нужны до 45 лет, массой не менее 65кг.
По всем вопросам обращаться в личку или по телефону:
8-901-054-01-41 Алексеева (Екимова) Анастасия https://vk.com/id82171277
8-905-139-52-23 Дрябина Наталья https://vk.com/dryabina
ПОЖАЛУЙСТА ПОМОГИТЕ Звонить в любое время!!! За репост СПАСИБО
94
ER 0.2320
Нашли только его пустую машину.
В Ярославле пятый день уже, как пропал таксист:
https://yarportal.ru/topic931733.html?view=findpost&p=32989864
58
ER 0.1367
Внимание! В Ярославле ушел из дома и не вернулся подросток:
https://yarportal.ru/topic931491.html?view=findpost&p=32969017
55
ER 0.1239
Сельский глава установил на селе самую настоящую демократию.
Важные решения принимает исходя из итогов опросов на своей страничке во “Вконтакте”, а еще планирует создать в мессенджере общий чат для всех селян:
https://yarportal.ru/topic930722.html?view=findpost&p=32916086
55
ER 0.1075
Сын погибшего сегодня в смертельном ДТП с двумя автобусами пассажира обратился к общественности с открытым письмом:
https://yarportal.ru/topic932306.html?view=findpost&p=33030726
Будет жаловаться на мэрию!
46
ER 0.1013
Зачем учиться 5 лет, если можно взять в руки метлу и зарабатывать столько же?
Тем более правительство предлагает неплохие пособия по безработице:
https://yarportal.ru/topic931192.html?view=findpost&p=33019604
44
ER 0.0904
Появилось видео с городских камер сегодняшней страшной смертельной аварии с двумя автобусами.
Теперь понятно, что произошло:
https://yarportal.ru/topic932306.html?view=findpost&p=33029285
34
ER 0.0700
Создание кластерных ролейCreate clustered roles
После создания отказоустойчивого кластера можно создать кластерные роли для размещения кластерных рабочих нагрузок.After you create the failover cluster, you can create clustered roles to host cluster workloads.
Примечание
Для кластерных ролей, требующих точки доступа клиента, в доменных службах Active Directory создается виртуальный объект-компьютер (VCO).For clustered roles that require a client access point, a virtual computer object (VCO) is created in AD DS. По умолчанию все объекты VCO для кластера создаются в том же контейнере или подразделении, что и объект CNO.By default, all VCOs for the cluster are created in the same container or OU as the CNO. Имейте в виду, что после создания кластера объект CNO можно переместить в любое подразделение.Realize that after you create a cluster, you can move the CNO to any OU.
Вот как можно создать кластерную роль:Here’s how to create a clustered role:
-
Чтобы на каждом узле отказоустойчивого кластера установить роль или компонент, необходимый для кластерной роли, используйте диспетчер сервера или Windows PowerShell.Use Server Manager or Windows PowerShell to install the role or feature that is required for a clustered role on each failover cluster node. Например, чтобы создать кластерный файловый сервер, установите роль файлового сервера на всех узлах кластера.For example, if you want to create a clustered file server, install the File Server role on all cluster nodes.
В таблице ниже приведены кластерные роли, которые можно настроить в мастере высокой доступности, и соответствующие роли или компоненты сервера, которые необходимо установить.The following table shows the clustered roles that you can configure in the High Availability Wizard and the associated server role or feature that you must install as a prerequisite.
Кластерная рольClustered Role Необходимая роль или компонентRole or Feature Prerequisite Сервер пространства именNamespace Server Пространства имен (часть роли файлового сервера)Namespaces (part of File Server role) Сервер пространства имен DFSDFS Namespace Server Роль DHCP-сервераDHCP Server role Координатор распределенных транзакций (DTC)Distributed Transaction Coordinator (DTC) НетNone Файловый серверFile Server Роль файлового сервераFile Server role Универсальное приложениеGeneric Application Не применимоNot applicable Универсальный сценарийGeneric Script Не применимоNot applicable Универсальная службаGeneric Service Не применимоNot applicable Брокер реплики Hyper-VHyper-V Replica Broker Роль Hyper-VHyper-V role Сервер цели iSCSIiSCSI Target Server Сервер цели iSCSI (часть роли файлового сервера)iSCSI Target Server (part of File Server role) iSNS-серверiSNS Server Компоненты службы iSNS-сервераiSNS Server Service feature Очередь сообщенийMessage Queuing Компонент службы очереди сообщенийMessage Queuing Services feature Другой серверOther Server НетNone Виртуальная машинаVirtual Machine Роль Hyper-VHyper-V role WINS-серверWINS Server Компонент WINS-сервераWINS Server feature -
В диспетчер отказоустойчивости кластеров разверните узел имя кластера, щелкните правой кнопкой мыши элемент ролии выберите пункт настроить роль.In Failover Cluster Manager, expand the cluster name, right-click Roles, and then select Configure Role.
-
Для создания кластерной роли выполните последовательность действий, предлагаемую мастером высокой доступности.Follow the steps in the High Availability Wizard to create the clustered role.
-
Чтобы проверить, создана ли кластерная роль, на панели Роли убедитесь в том, что роль имеет состояние Выполняется.To verify that the clustered role was created, in the Roles pane, make sure that the role has a status of Running. На панели “Роли” также указан узел владельца.The Roles pane also indicates the owner node. Чтобы протестировать отработку отказа, щелкните правой кнопкой мыши роль, выберите пункт переместить, а затем выберите пункт выбрать узел.To test failover, right-click the role, point to Move, and then select Select Node. В диалоговом окне Перемещение кластерной роли выберите нужный узел кластера и нажмите кнопку ОК.In the Move Clustered Role dialog box, select the desired cluster node, and then select OK. В столбце Узел владельца убедитесь в том, что узел владельца изменился.In the Owner Node column, verify that the owner node changed.
Как провести кластеризацию с помощью Line
Инструмент «Кластеризация» расположен в верхней панели управления
в сервисе проверки позиций Line:
Верхняя панель сервиса
Перейдите в раздел и нажмите «Создать задачу». Задайте ей название и настройте кластеризацию для вашей семантики:
- выберите поисковую систему, в которой продвигаетесь;
- обозначьте регион продвижения, в котором система будет смотреть запросы;
- выберите тип кластеризации: soft подойдет для контентных проектов, hard для запросов с высокой конкуренцией;
- отметьте, нужно ли проверять частотность и указывать ее в отчете;
- задайте порог кластеризации от одного до девяти;
- введите ключевые фразы в поле.
Запустите систему и через несколько минут сервис выдаст готовый отчет с группами ключевых слов. Его можно смотреть на экране или скачать в файле Excel.
Фрагмент демонстрационной кластеризации запросов в Line
Если вы нашли запросы, которые не входят в кластеры, не торопитесь их удалять. Проверьте, если они подходят теме вашего сайта, их все равно можно использовать: внедрите ключи на другие страницы — в статью блога или отзывы, добавьте в один из кластеров, куда они подходят по смыслу.
Что делать после кластеризации
Используйте полученные кластеры в работе:
- настраивайте рекламные кампании на разные группы;
- отслеживайте эффект РК по тематическим группам запросов;
- пишите контент, используя ключи из кластеров;
- заполняйте Title, Description, H1 и другие мета-теги страницы согласно запросам из одной группы;
- создавайте структуру сайта согласно разделению ключей;
- проверяйте позиции сайта.
Кластеризация делает работу с ключами точнее и проще — позволяет рассортировать массив ключей по группам, страницам и объявлениям. Используйте для этого сервисы, чтобы экономить свое время.
Реализованные типы анализа
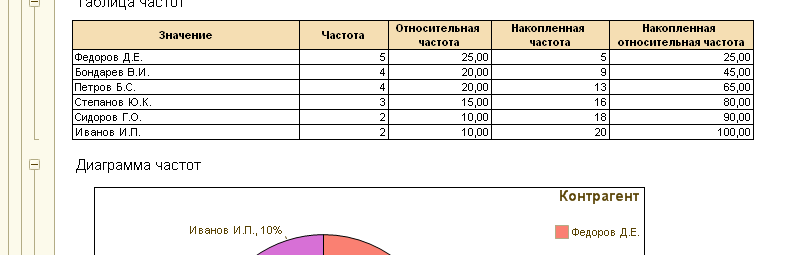
Общая статистика
Представляет собой механизм для сбора информации о данных, находящихся в исследуемой выборке. Этот тип анализа предназначен для предварительного исследования анализируемого источника данных.
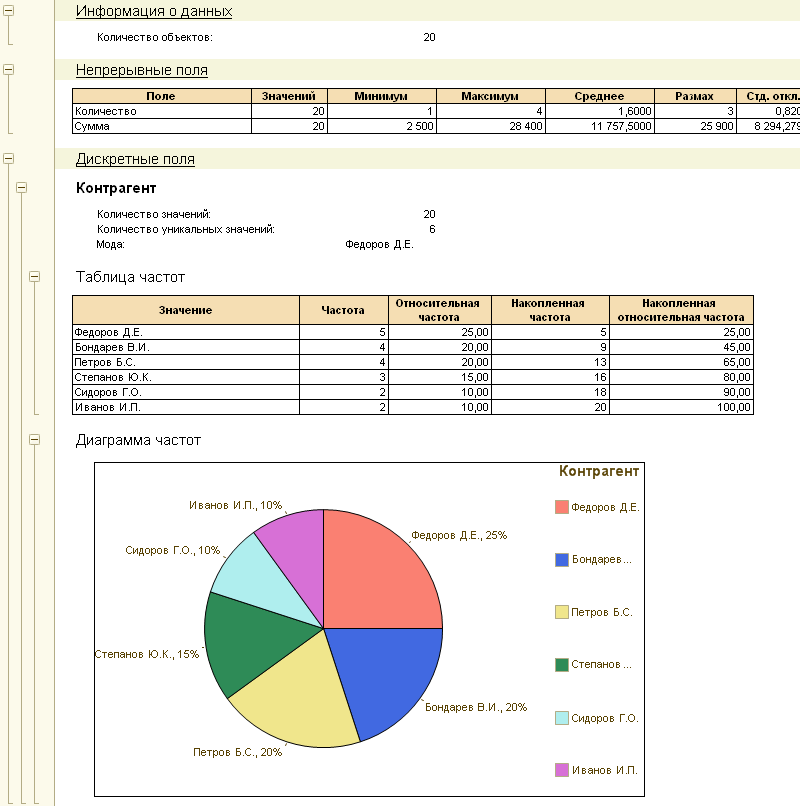
Анализ показывает ряд характеристик непрерывных и дискретных полей. Непрерывные поля содержат такие типы как Число, Дата. Для остальных типов используются дискретные поля.При выводе отчета в табличный документ заполняются круговые диаграммы для отображения состава полей.
Поиск ассоциаций
Данный тип анализа осуществляет поиск часто встречаемых вместе групп объектов или значений характеристик, а также производит поиск правил ассоциаций. Поиск ассоциаций может использоваться, например, для определения часто приобретаемых вместе товаров, или услуг:
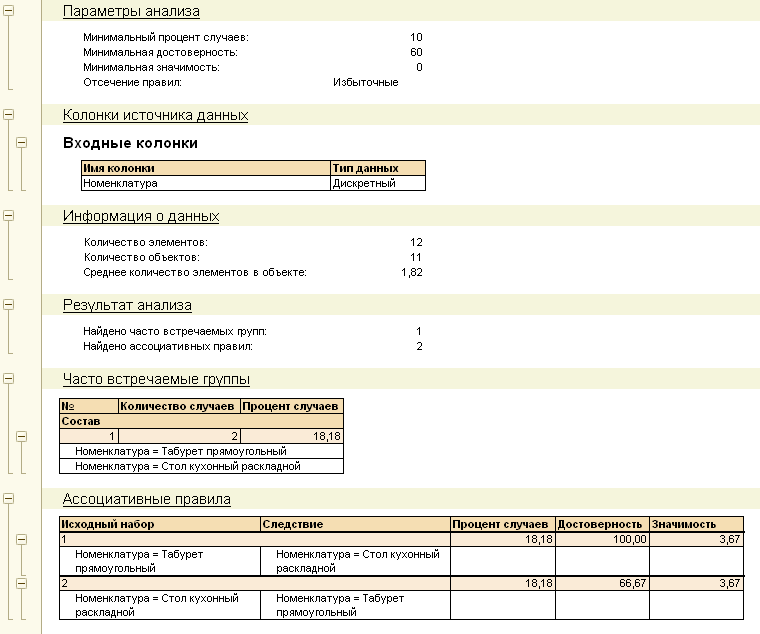
Этот тип анализа может работать с иерархическими данными, что позволяет, например, находить правила не только для конкретных товаров, но и для их групп
Важной особенностью этого типа анализа является возможность работать как с объектным источником данных, в котором каждая колонка содержит некоторую характеристику объекта, так и с событийным источником, где характеристики объекта располагаются в одной колонке.. Для облегчения восприятия результата предусмотрен механизм отсечения избыточных правил.
Для облегчения восприятия результата предусмотрен механизм отсечения избыточных правил.
Поиск последовательностей
Тип анализа поиск последовательностей позволяет выявлять в источнике данных последовательные цепочки событий. Например, это может быть цепочка товаров или услуг, которые часто последовательно приобретают клиенты:
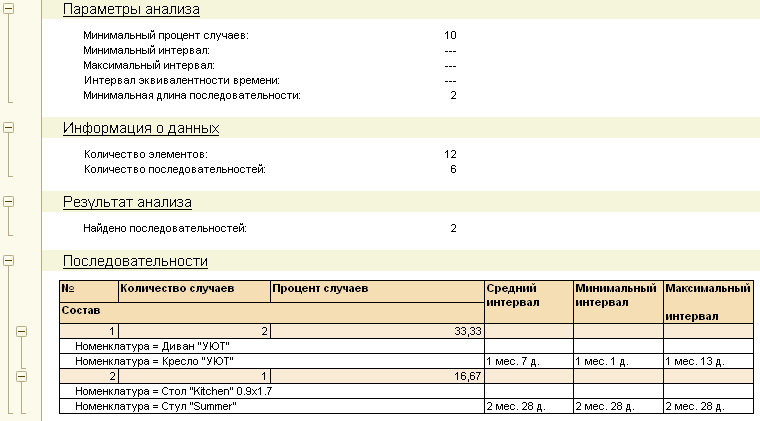
Этот тип анализа позволяет осуществлять поиск по иерархии, что дает возможность отслеживать не только последовательности конкретных событий, но и последовательности родительских групп.
Набор параметров анализа позволяет специалисту ограничивать временные расстояния между элементами искомых последовательностей, а также регулировать точность получаемых результатов.
Кластерный анализ
Кластерный анализ позволяет разделить исходный набор исследуемых объектов на группы объектов, таким образом, чтобы каждый объект был более схож с объектами из своей группы, чем с объектами других групп. Анализируя в дальнейшем полученные группы, называемые кластерами, можно определить, чем характеризуется та или иная группа, принять решение о методах работы с объектами различных групп. Например, при помощи кластерного анализа можно разделить клиентов, с которыми работает компания, на группы, для того, чтобы применять различные стратегии при работе с ними:
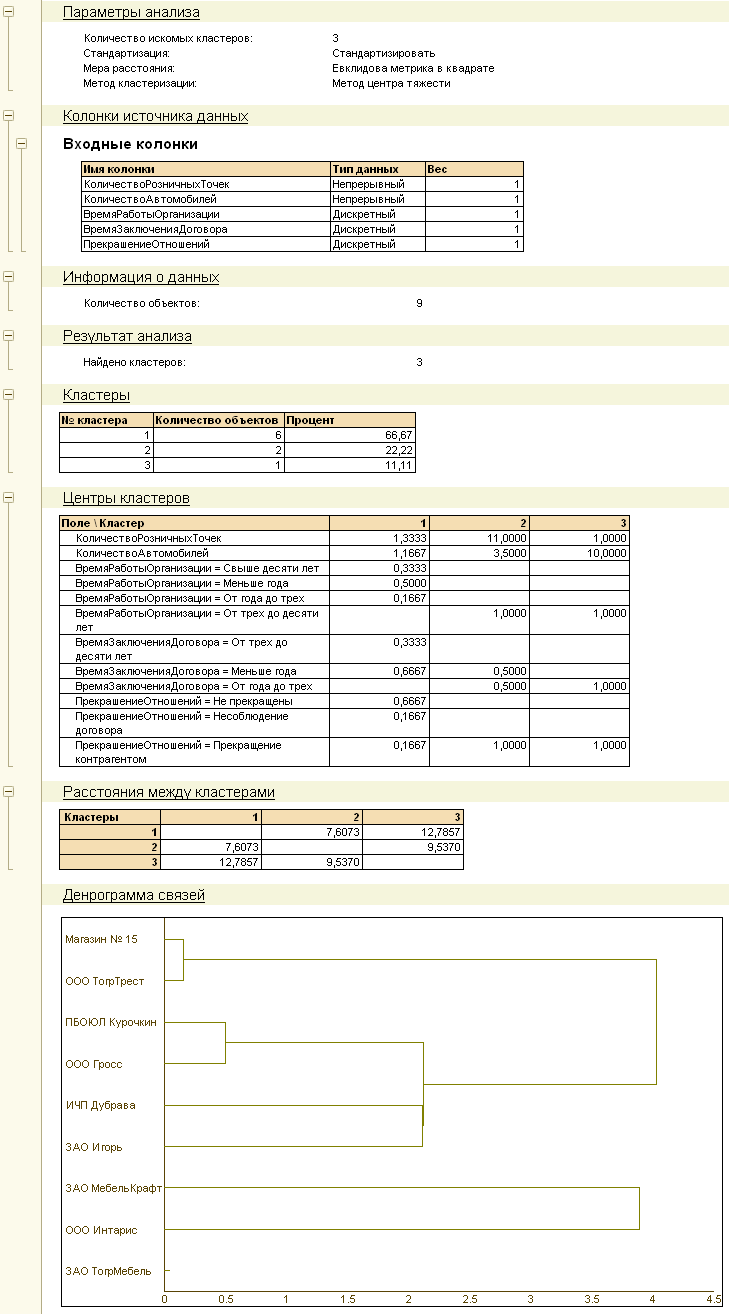
При помощи параметров кластерного анализа аналитик может настроить алгоритм, по которому будет производиться разбиение, а также может динамически изменять состав характеристик, учитываемых при анализе, настраивать для них весовые коэффициенты.
Результат кластеризации может быть выведен в дендрограмму — специальный объект, предназначенный для отображения последовательных связей между объектами.
Дерево решений
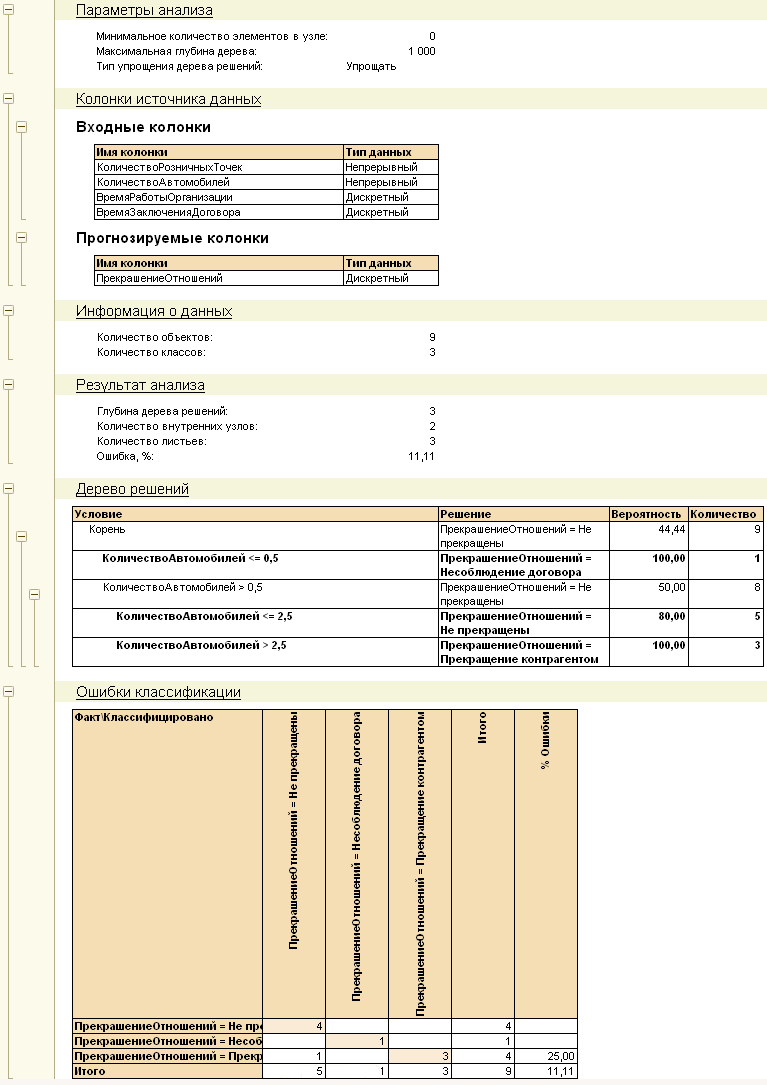
Тип анализа дерево решений позволяет построить иерархическую структуру классифицирующих правил, представленную в виде дерева.
Для построения дерева решений необходимо выбрать целевой атрибут, по которому будет строиться классификатор и ряд входных атрибутов, которые будут использоваться для создания правил. Целевой атрибут может содержать, например, информацию о том, перешел ли клиент к другому поставщику услуг, удачна ли была сделка, качественно ли была выполнена работа и т. д. Входными атрибутами, для примера, могут выступать возраст сотрудника, стаж его работы, материальное состояние клиента, количество сотрудников в компании и т. п.
Результат работы анализа представляется в виде дерева, каждый узел которого содержит некоторое условие. Для принятия решения, к какому классу следует отнести некий новый объект, необходимо, отвечая на вопросы в узлах, пройти цепочку от корня до листа дерева, переходя к дочерним узлам в случае утвердительного ответа и к соседнему узлу в случае отрицательного.
Набор параметров анализа позволяет регулировать точность полученного дерева:
Как кластеризуются запросы?
Инструмент анализирует выдачу Яндекс по каждому запросу и сравнивает ее с выдачей остальных запросов из списка. Если в ТОП-10 по разным запросам находятся те же релевантные страницы, то эти запросы определяются как схожие и помещаются в одну группу. Это значит что под них можно оптимизировать одну страницу.
Порог кластеризации запросов это количество совпавших релевантных страниц в выдаче, по разным запросам. Проще говоря, если ввести в Яндекс два запроса и в выдаче ТОП-10 будет две одинаковые страницы (две из десяти), то при выставлении “порога кластеризации 2” эти два запроса будут помещены в одну группу.
Минусы ручной группировки запросов
Группировка ключевых запросов, известная также как разбивка, выполняется SEO оптимизаторами непосредственно после сбора СЯ.
- При наличии большого количества запросов сложно в ручном режиме определить их схожесть между собой, приходится либо вводить каждый запрос в поиск, либо полагаться на интуицию/опыт, что может сыграть злую шутку при продвижении и не дать нужных результатов.
- Высокая стоимость, которая сформировалась за счет длительности процесса. На качественную разбивку семантики с 500 запросами на борту уходит в среднем 4..16 часов. Необходимо вычитать каждый запрос, определить его группу (наличие которой необходимо держать в голове), при необходимости перепроверить поиском или сервисами…бррр.
Плюсы автоматической группировки запросов
- Скорость выполнения разбивки примерно равна скорости звука. Система проверит выдачи каждого из запросов, сравнит их и даст возможность поправить возможные мелкие исключения вручную, после чего результат можно выгрузить в CSV файл (эксель).
- Точность результата, достигаемая за счет исключения человеческого фактора. Человек может отвлечься и потерять мысль, забыть, недопонять или просто не уметь делать разбивку правильно, с программой такие сложности не наблюдаются.
- Инструмент предоставляется полностью на бесплатной основе; он не требует помесячной заработной платы, отпусков, больничных; также у него нет графика работы: работает 24/7.
Разбивка является очень важным процессом при продвижении, она задает цели для оптимизации каждой страницы проекта и всего сайта в целом.
Be1.ru рекомендует оптимизировать страницы сайта по 3…10 запросам максимум. В противном случае есть опасность перемудрить и не продвинуться ни по одному из них, попав под фильтр за переспам.
Сравнение сервисов
В поиске самых популярных сервисов очень помог доклад Александра Ожгибесова на BDD-2017, к тем, что у него было добавлено еще несколько сервисов, получился такой список:
- Топвизор
- Pixelplus
- Serpstat
- Rush Analytics
- Just Magic
- Key Collector
- MindSerp
- Semparser
- KeyAssort
- coolakov.ru
Первое на что проверялись полученные в результате кластеризации эталонного ядра по этим сервисам группы – это не делает ли сервис слишком широкие группы. А именно не попали ли запросы из разных групп эталонного ядра в один кластер по версии сервиса.
Но только такого сравнения не достаточно. Сервисы делятся на два подхода к некластеризованному остатку фраз:
- сделать для них общую группу «Некластеризованные»;
- сделать для каждой некластеризованной фразы группу из нее одной.
В сравнении я использовал оба этих параметра в виде соотношения – какой процент фраз от общего количества попал не в свою группу.
Результаты сравнения:
- Топвизор
- разные группы эталона в одной по сервису – 4%
- одна группа эталона в разных по сервису – 7%
- Pixelplus
- разные группы эталона в одной по сервису – 0%
- одна группа эталона в разных по сервису – 7%
- Serpstat
- разные группы эталона в одной по сервису – 0%
- одна группа эталона в разных по сервису – 3%
- Rush Analytics (132 фразы, demo)
- разные группы эталона в одной по сервису – 11%
- одна группа эталона в разных по сервису – 8%
- Just Magic
- разные группы эталона в одной по сервису – 0%
- одна группа эталона в разных по сервису – 9%
- Key Collector
- разные группы эталона в одной по сервису – 12%
- одна группа эталона в разных по сервису – 16%
- MindSerp – не удалось получить демо, не выходят на связь
- Semparser
- разные группы эталона в одной по сервису – 1%
- одна группа эталона в разных по сервису – 3%
- KeyAssort
- разные группы эталона в одной по сервису – 1%
- одна группа эталона в разных по сервису – 1%
- coolakov.ru
- разные группы эталона в одной по сервису – 0%
- одна группа эталона в разных по сервису – 18%
Зачем нужны сервисы кластеризации?
В один кластер должны быть объединены только такие запросы, которые имеют хорошие шансы выйти в топ-10 поисковых систем с общей релевантной страницей. То есть, если по двум запросам в выдаче все страницы сайтов разные и нет пересечений, то следует относить их к разным кластерам. Также и наоборот: если два запроса возможно продвинуть на одной статье, то не следует разносить их на разные кластеры, чтобы не писать лишнего – бюджет на контент не резиновый.
Общая схема составления ТЗ на написание SEO-статьи следующая:
Сбор семантики – статистика поисковых систем, базы семантики, внутренняя статистика проекта;
Кластеризация автоматическая – сервис или программа для кластеризации по подобию топов;
«Посткластеризация» ручная – обработка того что не удалось кластеризовать автоматически;
Приоритезация – определение важности полученных запросов в каждом кластере;
Оформление ТЗ для копирайтера – лемматизация, LSI и различные указания для написания статей, по статье на каждый кластер.
Вот именно для второго пункта нужно было выбрать самый подходящий сервис автоматической кластеризации. Для этой цели я провел сравнительный анализ самых известных, на мой взгляд, сервисов.
Список источников
- pr-cy.ru
- v8.1c.ru
- borgi.ru
- be1.ru